标签:
难度: Medium
小扣在探索丛林的过程中,无意间发现了传说中“落寞的黄金之都”。而在这片建筑废墟的地带中,小扣使用探测仪监测到了存在某种带有「祝福」效果的力场。
经过不断的勘测记录,小扣将所有力场的分布都记录了下来。`forceField[i] = [x,y,side]` 表示第 `i` 片力场将覆盖以坐标 `(x,y)` 为中心,边长为 `side` 的正方形区域。
若任意一点的 **力场强度** 等于覆盖该点的力场数量,请求出在这片地带中 **力场强度** 最强处的 **力场强度**。
**注意:**
- 力场范围的边缘同样被力场覆盖。
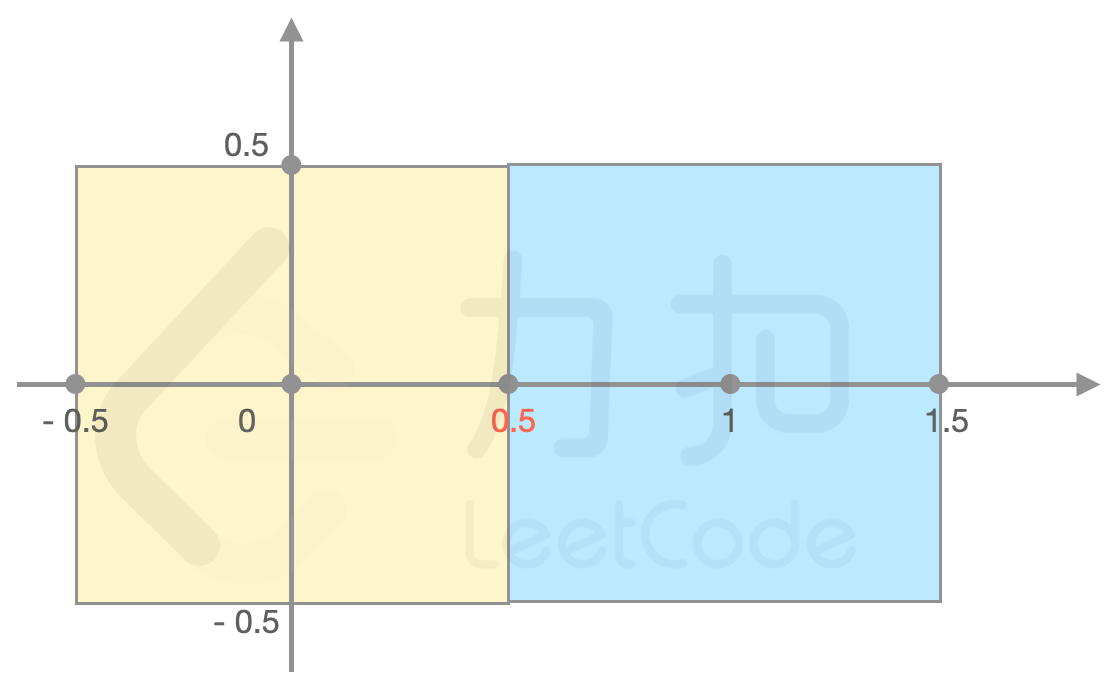
**示例 1:**
>输入:
>`forceField = [[0,0,1],[1,0,1]]`
>
>输出:`2`
>
>解释:如图所示,(0.5, 0) 处力场强度最强为 2, (0.5,-0.5)处力场强度同样是 2。
{:width=400px}
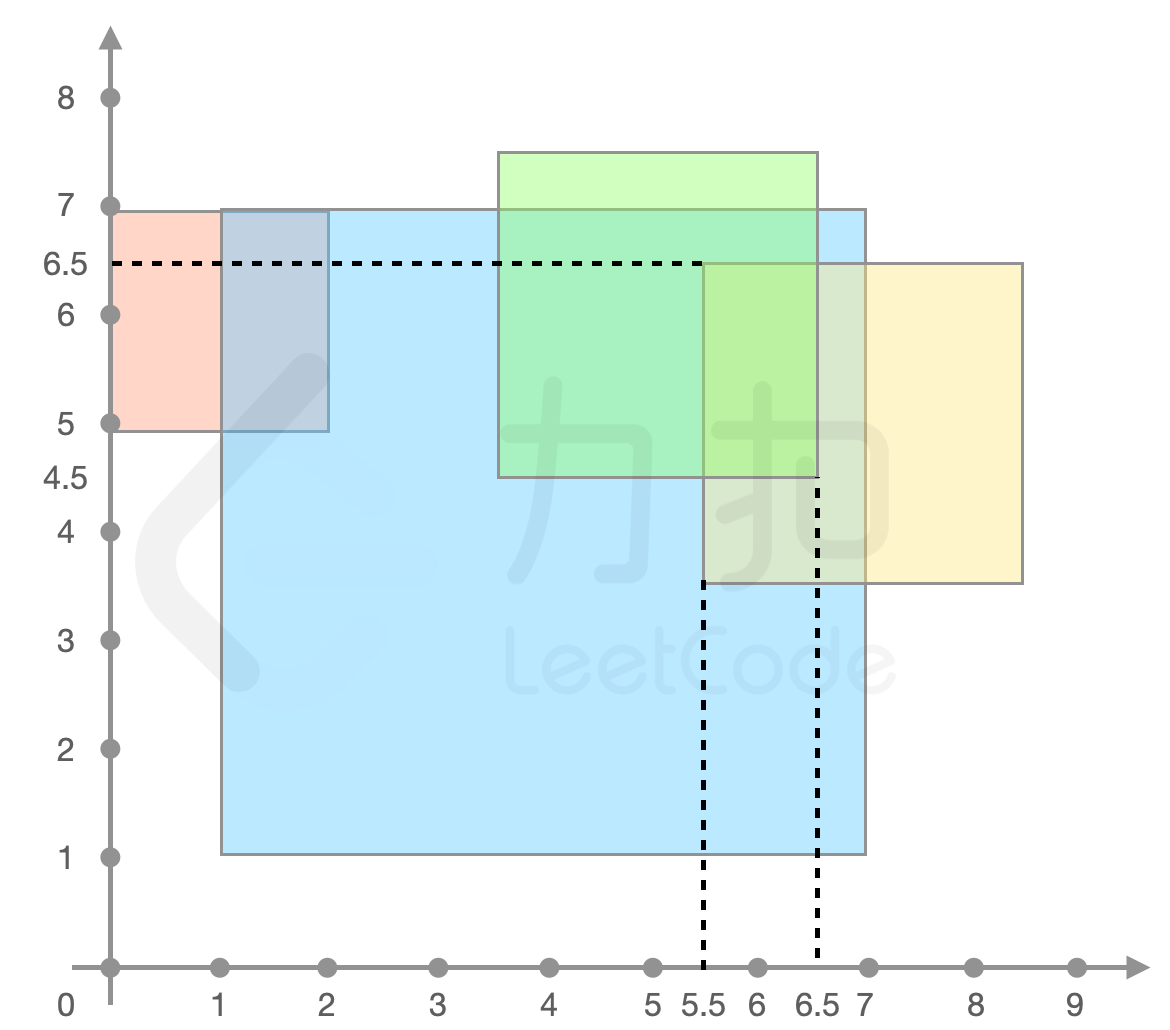
**示例 2:**
>输入:
>`forceField = [[4,4,6],[7,5,3],[1,6,2],[5,6,3]]`
>
>输出:`3`
>
>解释:如下图所示,
>`forceField[0]、forceField[1]、forceField[3]` 重叠的区域力场强度最大,返回 `3`
{:width=500px}
**提示:**
- `1 <= forceField.length <= 100`
- `forceField[i].length == 3`
- `0 <= forceField[i][0], forceField[i][1] <= 10^9`
- `1 <= forceField[i][2] <= 10^9`