难度: Easy
如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。
只有给定的树是单值二叉树时,才返回 true;否则返回 false。
示例 1:
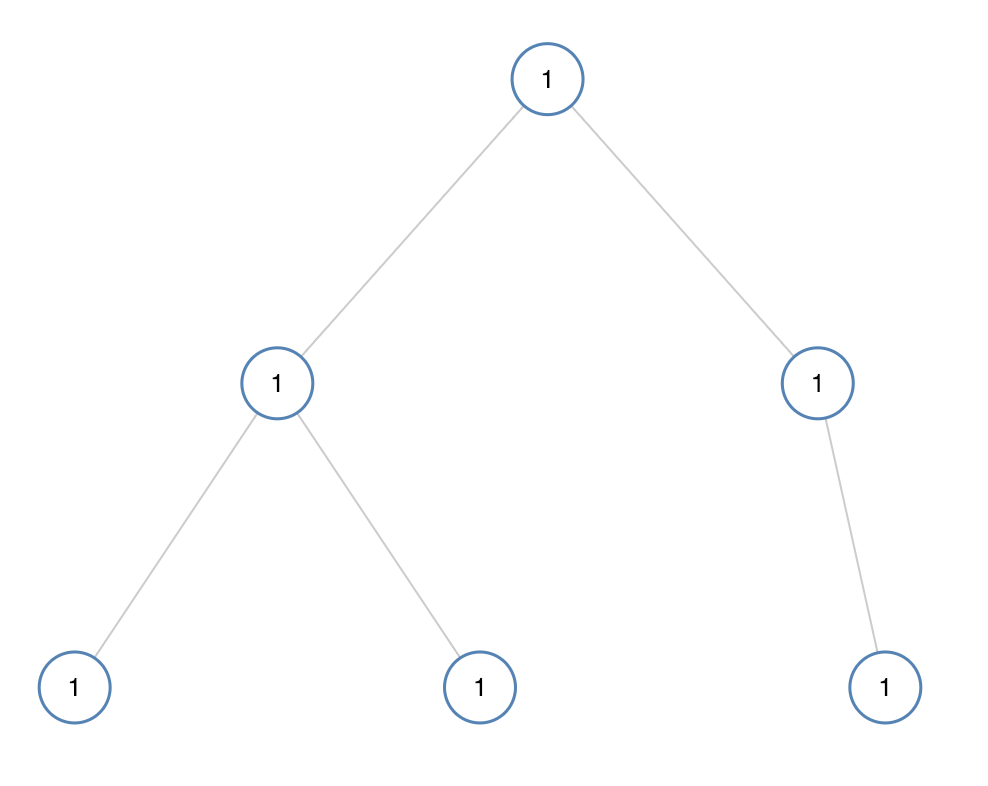
输入:[1,1,1,1,1,null,1] 输出:true
示例 2:
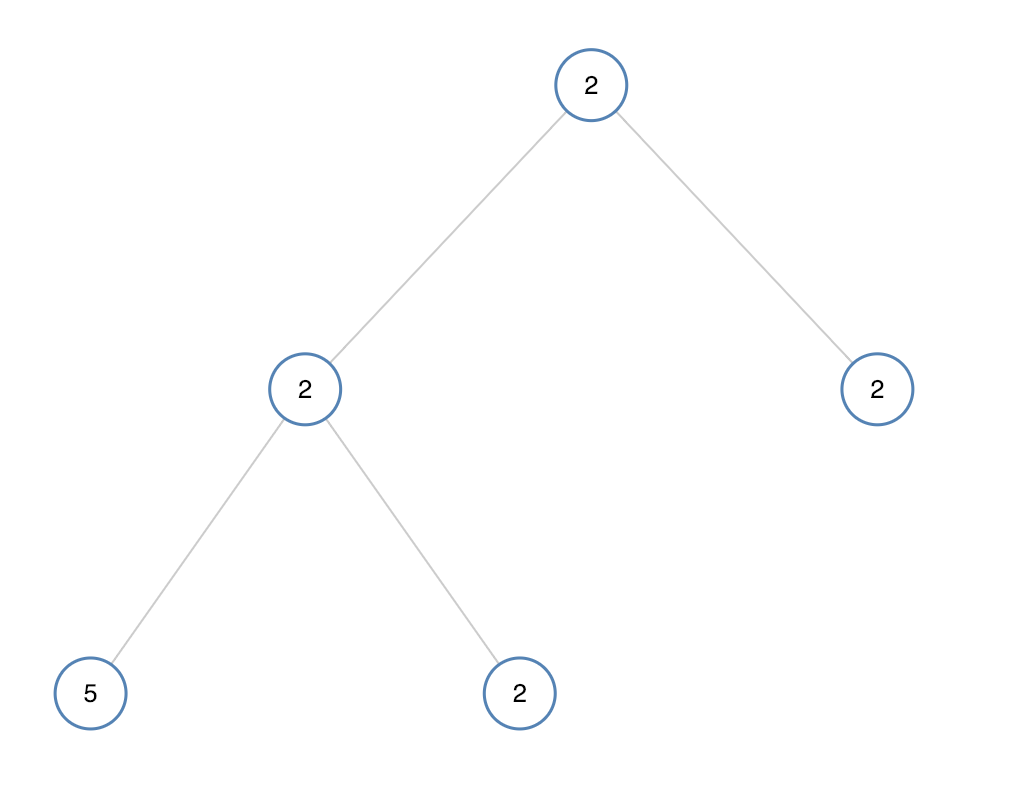
输入:[2,2,2,5,2] 输出:false
提示:
- 给定树的节点数范围是
[1, 100]。 - 每个节点的值都是整数,范围为
[0, 99]。
难度: Easy
如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。
只有给定的树是单值二叉树时,才返回 true;否则返回 false。
示例 1:
输入:[1,1,1,1,1,null,1] 输出:true
示例 2:
输入:[2,2,2,5,2] 输出:false
提示:
[1, 100]。[0, 99] 。运行时间: 23 ms
内存: 0.0 MB
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def isUnivalTree(self, root: Optional[TreeNode]) -> bool:
targetValue = root.val
stack = [root]
while stack:
curr = stack.pop()
if curr.val != targetValue:
return False
else:
if curr.left:
stack.append(curr.left)
if curr.right:
stack.append(curr.right)
return True
该题解采用了迭代的方式来遍历树,以判断是否所有节点的值都相同。首先,方法定义了一个目标值 targetValue,它是树根节点的值。然后,使用一个栈来存储待检测的树节点。循环会持续到栈为空,每次循环中,从栈中弹出一个节点并检查其值是否等于目标值。如果不等,则立即返回 False。如果相等,则将该节点的左右子节点(如果存在)加入栈中继续检查。如果所有节点检查完毕,且都与目标值相同,则返回 True。
时间复杂度: O(n)
空间复杂度: O(n)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def isUnivalTree(self, root: Optional[TreeNode]) -> bool:
targetValue = root.val # 目标值为根节点的值
stack = [root] # 使用栈来进行迭代遍历
while stack:
curr = stack.pop() # 弹出栈顶元素
if curr.val != targetValue:
return False # 如果当前节点值不等于目标值,返回 False
else:
if curr.left:
stack.append(curr.left) # 将左子节点加入栈中
if curr.right:
stack.append(curr.right) # 将右子节点加入栈中
return True # 如果所有节点值都与目标值相同,返回 True
在迭代遍历中选择使用栈而不是队列,主要是因为栈提供了后进先出的特性,这使得算法可以深度优先遍历二叉树。使用栈进行深度优先遍历(DFS)通常在内存使用上更加高效,因为它只需要保持当前路径上的节点,而不像宽度优先遍历(使用队列实现)那样可能需要存储整层节点。此外,对于某些问题,DFS可能更快找到解决方案,尤其是在树的结构不平衡时。然而,对于单值二叉树的检查,使用栈或队列的效率差异不大,因为无论如何都需要访问所有节点。
在本题解中,null节点不会被加入栈中。在迭代过程中,只有当节点存在(即非null)时,才会将其左右子节点加入栈中进行后续的值比较。这种处理方式确保了算法不会在null节点上执行无意义的操作,同时也防止了可能的空指针异常。因此,这种方法自然而然地处理了非满二叉树中的null节点。
如果初始根节点是null,根据题目的定义,空树不包含任何节点,因此可以认为它是单值二叉树(因为没有任何不符合条件的节点)。在实现中,应该在开始遍历前先检查根节点是否为null。如果是null,直接返回True表示这是一个单值二叉树。这样的处理可以避免后续的空指针错误,并且是逻辑上正确的处理方式。