难度: Medium
给你一个整数 n 和一个下标从 0 开始的 二维数组 queries ,其中 queries[i] = [typei, indexi, vali] 。
一开始,给你一个下标从 0 开始的 n x n 矩阵,所有元素均为 0 。每一个查询,你需要执行以下操作之一:
- 如果
typei == 0,将第indexi行的元素全部修改为vali,覆盖任何之前的值。 - 如果
typei == 1,将第indexi列的元素全部修改为vali,覆盖任何之前的值。
请你执行完所有查询以后,返回矩阵中所有整数的和。
示例 1:
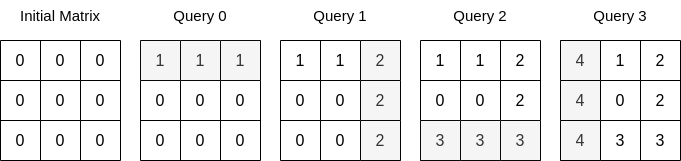
输入:n = 3, queries = [[0,0,1],[1,2,2],[0,2,3],[1,0,4]] 输出:23 解释:上图展示了每个查询以后矩阵的值。所有操作执行完以后,矩阵元素之和为 23 。
示例 2:
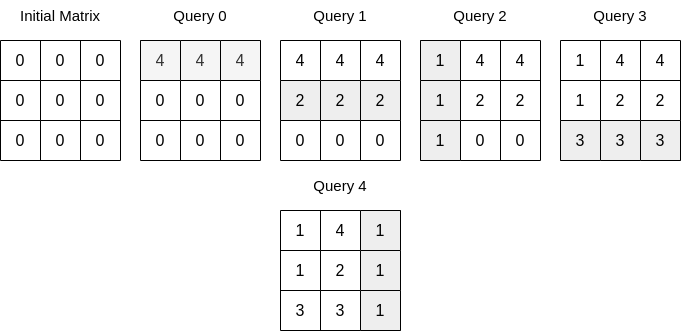
输入:n = 3, queries = [[0,0,4],[0,1,2],[1,0,1],[0,2,3],[1,2,1]] 输出:17 解释:上图展示了每一个查询操作之后的矩阵。所有操作执行完以后,矩阵元素之和为 17 。
提示:
1 <= n <= 1041 <= queries.length <= 5 * 104queries[i].length == 30 <= typei <= 10 <= indexi < n0 <= vali <= 105