难度: Hard
给定一个无向、连通的树。树中有 n 个标记为 0...n-1 的节点以及 n-1 条边 。
给定整数 n 和数组 edges , edges[i] = [ai, bi]表示树中的节点 ai 和 bi 之间有一条边。
返回长度为 n 的数组 answer ,其中 answer[i] 是树中第 i 个节点与所有其他节点之间的距离之和。
示例 1:
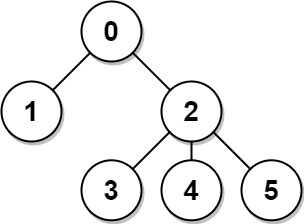
输入: n = 6, edges = [[0,1],[0,2],[2,3],[2,4],[2,5]] 输出: [8,12,6,10,10,10] 解释: 树如图所示。 我们可以计算出 dist(0,1) + dist(0,2) + dist(0,3) + dist(0,4) + dist(0,5) 也就是 1 + 1 + 2 + 2 + 2 = 8。 因此,answer[0] = 8,以此类推。
示例 2:

输入: n = 1, edges = [] 输出: [0]
示例 3:
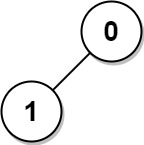
输入: n = 2, edges = [[1,0]] 输出: [1,1]
提示:
1 <= n <= 3 * 104edges.length == n - 1edges[i].length == 20 <= ai, bi < nai != bi- 给定的输入保证为有效的树