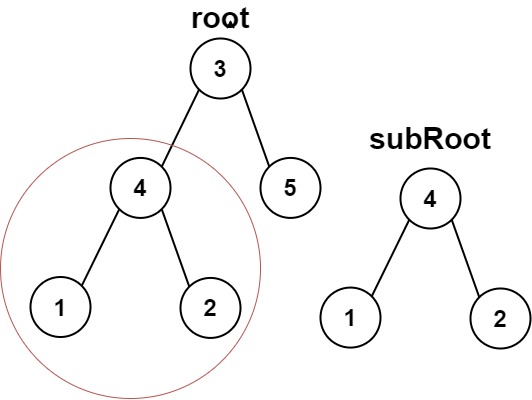
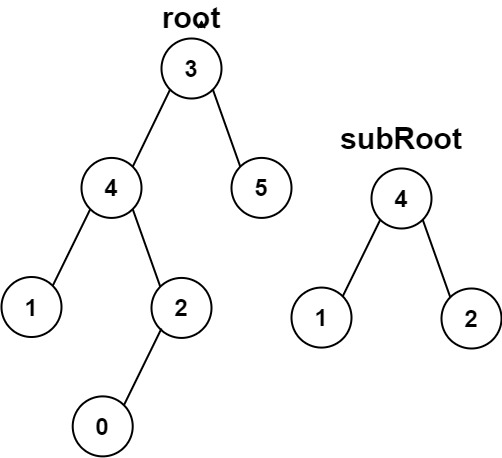
该题解使用了哈希的思想。首先通过 searchsub 函数计算出子树 subRoot 的哈希值,然后在主树 root 中通过 searchmain 函数查找是否存在一个子树的哈希值与 subRoot 的哈希值相等。如果存在,则说明主树中包含了与 subRoot 结构相同的子树,返回 True;否则返回 False。在计算哈希值时,使用了节点的值、左子树的哈希值和右子树的哈希值,并通过质数相乘的方式组合,以尽量避免哈希冲突。
时间复杂度: O(m + n)
空间复杂度: O(n)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def isSubtree(self, root: Optional[TreeNode], subRoot: Optional[TreeNode]) -> bool:
def searchsub(root):
if not root:
return 0
# 计算子树的哈希值
return ((root.val + 1000079) + (searchsub(root.left) * 31 + searchsub(root.right) * 179)) % int(1e10 + 7)
# 计算子树 subRoot 的哈希值
num = searchsub(subRoot)
ans = [False]
def searchmain(root):
if not root:
return 0
# 计算主树的哈希值
val = ((root.val + 1000079) + (searchmain(root.left) * 31 + searchmain(root.right) * 179)) % int(1e10 + 7)
# 比较主树的哈希值与子树的哈希值
if val == num:
ans[0] = True
return val
searchmain(root)
return ans[0]