难度: Hard
有 n 个项目,每个项目或者不属于任何小组,或者属于 m 个小组之一。group[i] 表示第 i 个项目所属的小组,如果第 i 个项目不属于任何小组,则 group[i] 等于 -1。项目和小组都是从零开始编号的。可能存在小组不负责任何项目,即没有任何项目属于这个小组。
请你帮忙按要求安排这些项目的进度,并返回排序后的项目列表:
- 同一小组的项目,排序后在列表中彼此相邻。
- 项目之间存在一定的依赖关系,我们用一个列表
beforeItems来表示,其中beforeItems[i]表示在进行第i个项目前(位于第i个项目左侧)应该完成的所有项目。
如果存在多个解决方案,只需要返回其中任意一个即可。如果没有合适的解决方案,就请返回一个 空列表 。
示例 1:
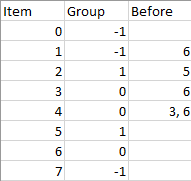
输入:n = 8, m = 2, group = [-1,-1,1,0,0,1,0,-1], beforeItems = [[],[6],[5],[6],[3,6],[],[],[]] 输出:[6,3,4,1,5,2,0,7]
示例 2:
输入:n = 8, m = 2, group = [-1,-1,1,0,0,1,0,-1], beforeItems = [[],[6],[5],[6],[3],[],[4],[]] 输出:[] 解释:与示例 1 大致相同,但是在排序后的列表中,4 必须放在 6 的前面。
提示:
1 <= m <= n <= 3 * 104group.length == beforeItems.length == n-1 <= group[i] <= m - 10 <= beforeItems[i].length <= n - 10 <= beforeItems[i][j] <= n - 1i != beforeItems[i][j]beforeItems[i]不含重复元素