难度: Medium
给定一颗根结点为 root 的二叉树,树中的每一个结点都有一个 [0, 25] 范围内的值,分别代表字母 'a' 到 'z'。
返回 按字典序最小 的字符串,该字符串从这棵树的一个叶结点开始,到根结点结束。
注:字符串中任何较短的前缀在 字典序上 都是 较小 的:
- 例如,在字典序上
"ab"比"aba"要小。叶结点是指没有子结点的结点。
节点的叶节点是没有子节点的节点。
示例 1:
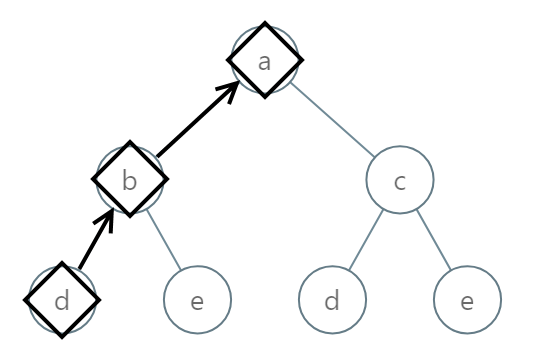
输入:root = [0,1,2,3,4,3,4] 输出:"dba"
示例 2:
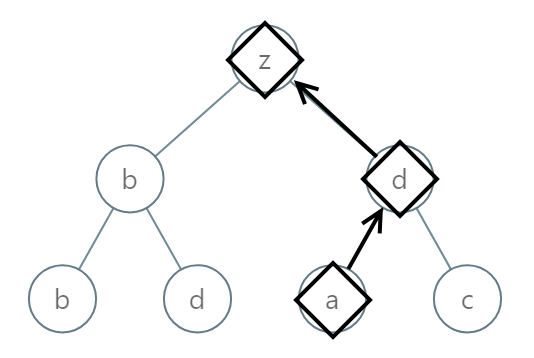
输入:root = [25,1,3,1,3,0,2] 输出:"adz"
示例 3:
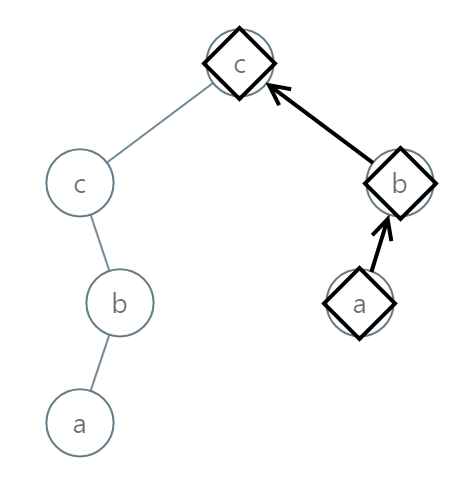
输入:root = [2,2,1,null,1,0,null,0] 输出:"abc"
提示:
- 给定树的结点数在
[1, 8500]范围内 0 <= Node.val <= 25