难度: Hard
给你一个 m x n 的矩阵 matrix ,请你返回一个新的矩阵 answer ,其中 answer[row][col] 是 matrix[row][col] 的秩。
每个元素的 秩 是一个整数,表示这个元素相对于其他元素的大小关系,它按照如下规则计算:
- 秩是从 1 开始的一个整数。
- 如果两个元素
p和q在 同一行 或者 同一列 ,那么:- 如果
p < q,那么rank(p) < rank(q) - 如果
p == q,那么rank(p) == rank(q) - 如果
p > q,那么rank(p) > rank(q)
- 如果
- 秩 需要越 小 越好。
题目保证按照上面规则 answer 数组是唯一的。
示例 1:
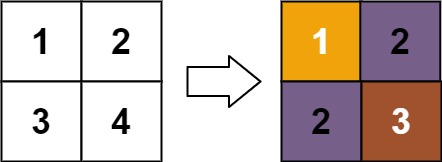
输入:matrix = [[1,2],[3,4]] 输出:[[1,2],[2,3]] 解释: matrix[0][0] 的秩为 1 ,因为它是所在行和列的最小整数。 matrix[0][1] 的秩为 2 ,因为 matrix[0][1] > matrix[0][0] 且 matrix[0][0] 的秩为 1 。 matrix[1][0] 的秩为 2 ,因为 matrix[1][0] > matrix[0][0] 且 matrix[0][0] 的秩为 1 。 matrix[1][1] 的秩为 3 ,因为 matrix[1][1] > matrix[0][1], matrix[1][1] > matrix[1][0] 且 matrix[0][1] 和 matrix[1][0] 的秩都为 2 。
示例 2:
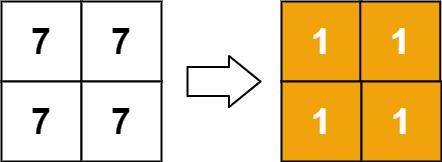
输入:matrix = [[7,7],[7,7]] 输出:[[1,1],[1,1]]
示例 3:
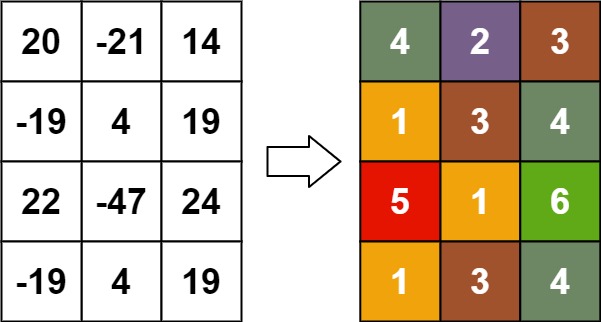
输入:matrix = [[20,-21,14],[-19,4,19],[22,-47,24],[-19,4,19]] 输出:[[4,2,3],[1,3,4],[5,1,6],[1,3,4]]
示例 4:
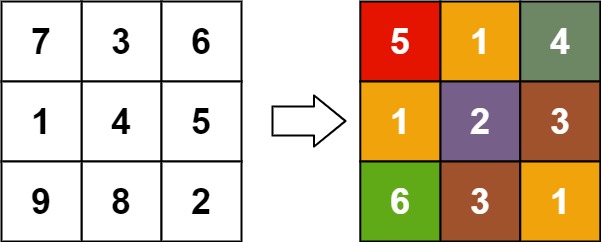
输入:matrix = [[7,3,6],[1,4,5],[9,8,2]] 输出:[[5,1,4],[1,2,3],[6,3,1]]
提示:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 500-109 <= matrix[row][col] <= 109