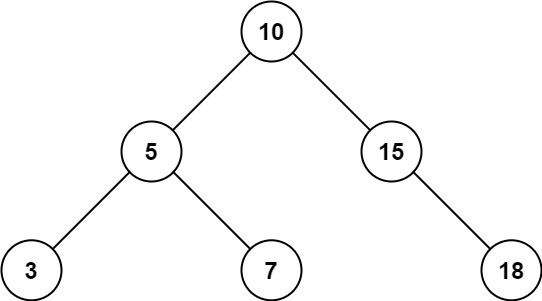
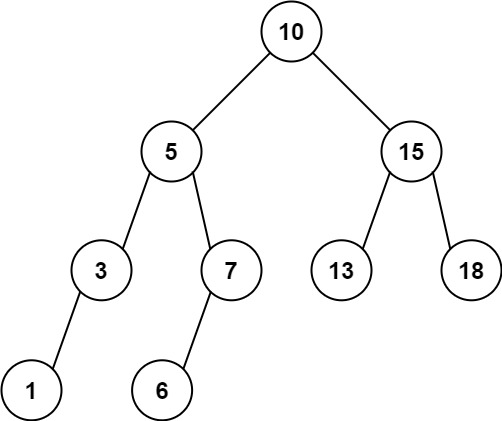
此题解采用递归方法解决二叉搜索树中的范围求和问题。首先,检查当前节点是否为空,若为空,则返回和为0。其次,根据二叉搜索树的性质,如果当前节点的值小于下限low,则只需递归右子树;如果当前节点的值大于上限high,则只需递归左子树。如果当前节点的值在[low, high]范围内,则将其值加到总和中,并继续递归左右子树。这种方法有效利用了二叉搜索树的性质,减少了不必要的节点访问。
时间复杂度: O(n)
空间复杂度: O(h)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def rangeSumBST(self, root: Optional[TreeNode], low: int, high: int) -> int:
if root is None: # 检查当前节点是否为空
return 0
if root.val < low: # 当前节点值小于下限,只递归右子树
return self.rangeSumBST(root.right, low, high)
if root.val > high: # 当前节点值大于上限,只递归左子树
return self.rangeSumBST(root.left, low, high)
# 当前节点值在范围内,计算总和并递归左右子树
return root.val + self.rangeSumBST(root.left, low, high) + self.rangeSumBST(root.right, low, high)