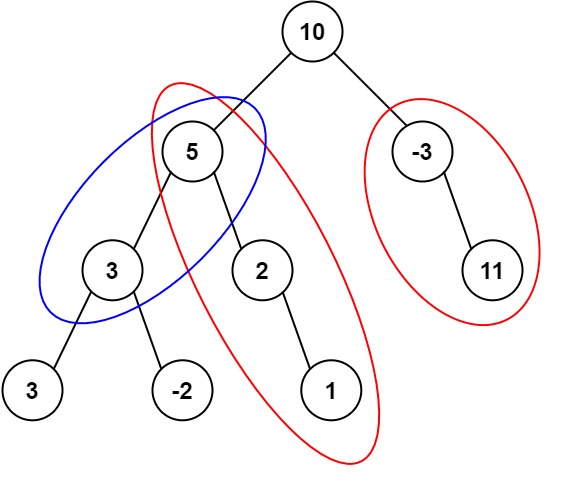
这个题解采用递归的方式对二叉树进行深度优先遍历。主函数 pathSum 递归调用自身,分别以根节点的左右子节点作为新的根节点,继续寻找满足条件的路径。在每次调用 pathSum 时,都会调用 helper 函数,helper 函数则从当前节点开始,使用 dfs 函数进行路径搜索。dfs 函数会在找到一条满足条件的路径时,将 ret 计数器加1,然后继续搜索左右子树,寻找更多可能的路径。
时间复杂度: O(n^2)
空间复杂度: O(n)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
ret = 0
def pathSum(self, root: TreeNode, sum: int) -> int:
if root is None:
return self.ret
self.helper(root, sum) # 从根节点开始搜索路径
self.pathSum(root.left, sum) # 递归搜索左子树
self.pathSum(root.right, sum) # 递归搜索右子树
return self.ret
def helper(self, root, s):
def dfs(root, s):
if root is None:
return
s -= root.val
if s == 0:
self.ret += 1 # 找到一条满足条件的路径,计数器加1
dfs(root.left, s) # 递归搜索左子树
dfs(root.right, s) # 递归搜索右子树
dfs(root, s) # 从当前节点开始搜索路径