难度: Medium
给你一棵树(即,一个连通的无环无向图),这棵树由编号从 0 到 n - 1 的 n 个节点组成,且恰好有 n - 1 条 edges 。树的根节点为节点 0 ,树上的每一个节点都有一个标签,也就是字符串 labels 中的一个小写字符(编号为 i 的 节点的标签就是 labels[i] )
边数组 edges 以 edges[i] = [ai, bi] 的形式给出,该格式表示节点 ai 和 bi 之间存在一条边。
返回一个大小为 n 的数组,其中 ans[i] 表示第 i 个节点的子树中与节点 i 标签相同的节点数。
树 T 中的子树是由 T 中的某个节点及其所有后代节点组成的树。
示例 1:
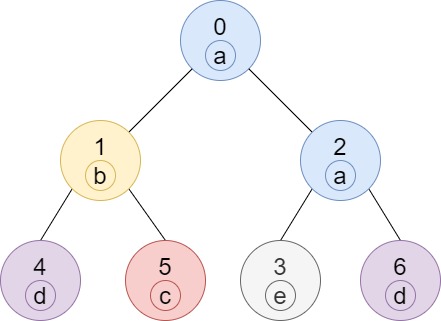
输入:n = 7, edges = [[0,1],[0,2],[1,4],[1,5],[2,3],[2,6]], labels = "abaedcd" 输出:[2,1,1,1,1,1,1] 解释:节点 0 的标签为 'a' ,以 'a' 为根节点的子树中,节点 2 的标签也是 'a' ,因此答案为 2 。注意树中的每个节点都是这棵子树的一部分。 节点 1 的标签为 'b' ,节点 1 的子树包含节点 1、4 和 5,但是节点 4、5 的标签与节点 1 不同,故而答案为 1(即,该节点本身)。
示例 2:
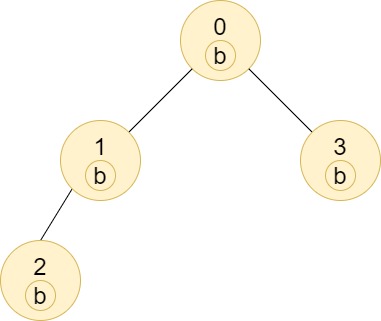
输入:n = 4, edges = [[0,1],[1,2],[0,3]], labels = "bbbb" 输出:[4,2,1,1] 解释:节点 2 的子树中只有节点 2 ,所以答案为 1 。 节点 3 的子树中只有节点 3 ,所以答案为 1 。 节点 1 的子树中包含节点 1 和 2 ,标签都是 'b' ,因此答案为 2 。 节点 0 的子树中包含节点 0、1、2 和 3,标签都是 'b',因此答案为 4 。
示例 3:
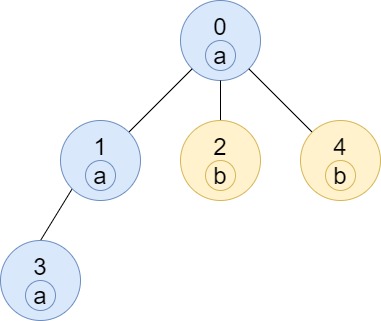
输入:n = 5, edges = [[0,1],[0,2],[1,3],[0,4]], labels = "aabab" 输出:[3,2,1,1,1]
提示:
1 <= n <= 10^5edges.length == n - 1edges[i].length == 20 <= ai, bi < nai != bilabels.length == nlabels仅由小写英文字母组成