难度: Medium
给你一个大小为 m x n 的二进制矩阵 grid ,其中 0 表示一个海洋单元格、1 表示一个陆地单元格。
一次 移动 是指从一个陆地单元格走到另一个相邻(上、下、左、右)的陆地单元格或跨过 grid 的边界。
返回网格中 无法 在任意次数的移动中离开网格边界的陆地单元格的数量。
示例 1:
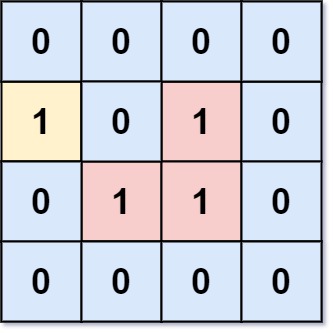
输入:grid = [[0,0,0,0],[1,0,1,0],[0,1,1,0],[0,0,0,0]] 输出:3 解释:有三个 1 被 0 包围。一个 1 没有被包围,因为它在边界上。
示例 2:
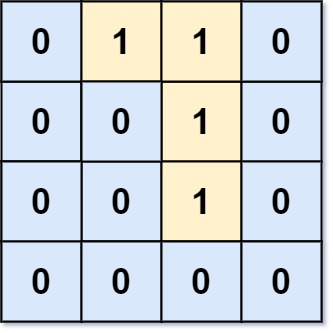
输入:grid = [[0,1,1,0],[0,0,1,0],[0,0,1,0],[0,0,0,0]] 输出:0 解释:所有 1 都在边界上或可以到达边界。
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 500grid[i][j]的值为0或1