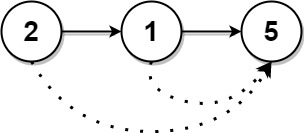
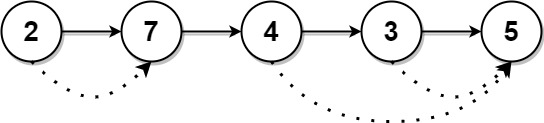
这个解决方案首先将链表的值转换为一个列表,然后利用单调栈解决'下一个更大的元素'问题。通过遍历链表将所有值存储在列表中,随后使用单调栈技术来快速查找每个元素右侧第一个更大的值。遍历值列表时,对于每个元素,检查栈顶元素是否代表一个较小的值。如果是,栈顶元素出栈并更新结果数组,表明找到了较小元素右侧的更大值。如果当前元素不比栈顶元素大,或栈为空,则当前元素索引入栈。这样确保栈内元素始终保持单调递减。
时间复杂度: O(n)
空间复杂度: O(n)
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def nextLargerNodes(self, head: Optional[ListNode]) -> List[int]:
# 使用单调栈解决下一个更大的节点问题
val_list = [] # 将链表的值存储到列表中
cur = head # 初始化当前节点为头节点
while cur:
value = cur.val # 获取当前节点的值
val_list.append(value) # 添加到列表中
cur = cur.next # 移动到下一个节点
st = [] # 初始化单调栈
res = [0] * len(val_list) # 初始化结果数组,所有值默认为0
for i, val in enumerate(val_list): # 遍历每个节点值
while st and val > val_list[st[-1]]: # 如果栈不空,且当前值大于栈顶值
j = st.pop() # 弹出栈顶元素
res[j] = val # 更新结果数组
st.append(i) # 当前元素索引入栈
return res # 返回结果数组