难度: Easy
给定一个 n 叉树的根节点 root ,返回 其节点值的 后序遍历 。
n 叉树 在输入中按层序遍历进行序列化表示,每组子节点由空值 null 分隔(请参见示例)。
示例 1:
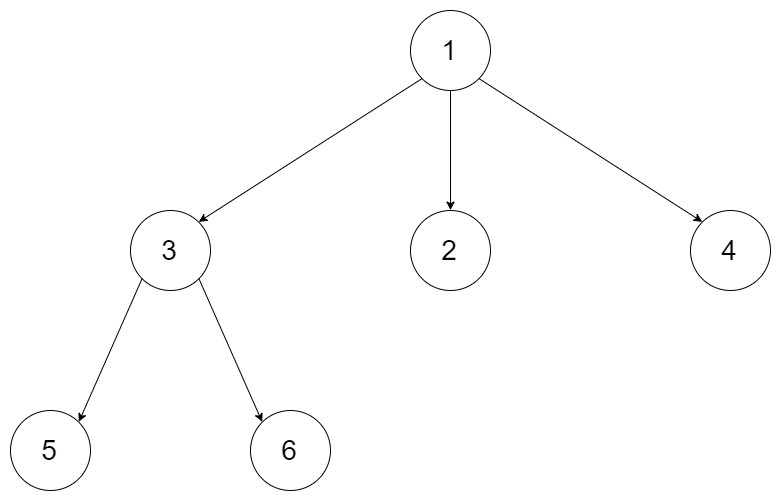
输入:root = [1,null,3,2,4,null,5,6] 输出:[5,6,3,2,4,1]
示例 2:
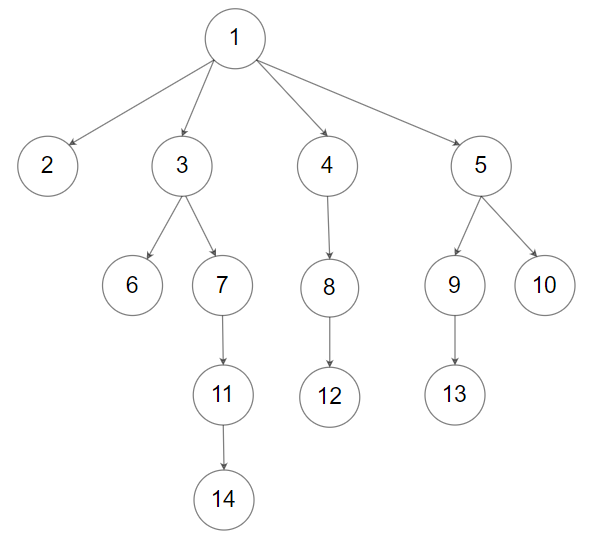
输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14] 输出:[2,6,14,11,7,3,12,8,4,13,9,10,5,1]
提示:
- 节点总数在范围
[0, 104]内 0 <= Node.val <= 104- n 叉树的高度小于或等于
1000
进阶:递归法很简单,你可以使用迭代法完成此题吗?