难度: Hard
现有一棵由 n 个节点组成的无向树,节点按从 0 到 n - 1 编号。给你一个整数 n 和一个长度为 n - 1 的二维整数数组 edges ,其中 edges[i] = [ui, vi, wi] 表示树中存在一条位于节点 ui 和节点 vi 之间、权重为 wi 的边。
另给你一个长度为 m 的二维整数数组 queries ,其中 queries[i] = [ai, bi] 。对于每条查询,请你找出使从 ai 到 bi 路径上每条边的权重相等所需的 最小操作次数 。在一次操作中,你可以选择树上的任意一条边,并将其权重更改为任意值。
注意:
- 查询之间 相互独立 的,这意味着每条新的查询时,树都会回到 初始状态 。
- 从
ai到bi的路径是一个由 不同 节点组成的序列,从节点ai开始,到节点bi结束,且序列中相邻的两个节点在树中共享一条边。
返回一个长度为 m 的数组 answer ,其中 answer[i] 是第 i 条查询的答案。
示例 1:
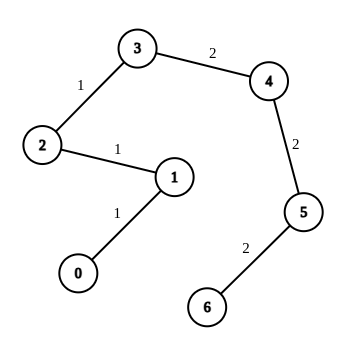
输入:n = 7, edges = [[0,1,1],[1,2,1],[2,3,1],[3,4,2],[4,5,2],[5,6,2]], queries = [[0,3],[3,6],[2,6],[0,6]] 输出:[0,0,1,3] 解释:第 1 条查询,从节点 0 到节点 3 的路径中的所有边的权重都是 1 。因此,答案为 0 。 第 2 条查询,从节点 3 到节点 6 的路径中的所有边的权重都是 2 。因此,答案为 0 。 第 3 条查询,将边 [2,3] 的权重变更为 2 。在这次操作之后,从节点 2 到节点 6 的路径中的所有边的权重都是 2 。因此,答案为 1 。 第 4 条查询,将边 [0,1]、[1,2]、[2,3] 的权重变更为 2 。在这次操作之后,从节点 0 到节点 6 的路径中的所有边的权重都是 2 。因此,答案为 3 。 对于每条查询 queries[i] ,可以证明 answer[i] 是使从 ai 到 bi 的路径中的所有边的权重相等的最小操作次数。
示例 2:
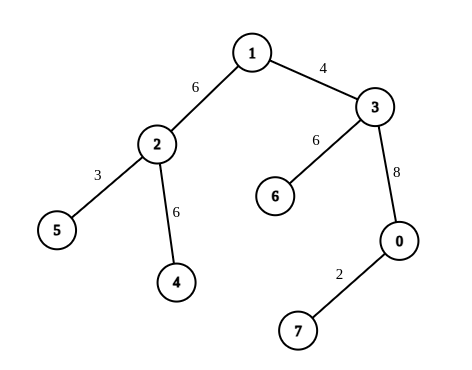
输入:n = 8, edges = [[1,2,6],[1,3,4],[2,4,6],[2,5,3],[3,6,6],[3,0,8],[7,0,2]], queries = [[4,6],[0,4],[6,5],[7,4]] 输出:[1,2,2,3] 解释:第 1 条查询,将边 [1,3] 的权重变更为 6 。在这次操作之后,从节点 4 到节点 6 的路径中的所有边的权重都是 6 。因此,答案为 1 。 第 2 条查询,将边 [0,3]、[3,1] 的权重变更为 6 。在这次操作之后,从节点 0 到节点 4 的路径中的所有边的权重都是 6 。因此,答案为 2 。 第 3 条查询,将边 [1,3]、[5,2] 的权重变更为 6 。在这次操作之后,从节点 6 到节点 5 的路径中的所有边的权重都是 6 。因此,答案为 2 。 第 4 条查询,将边 [0,7]、[0,3]、[1,3] 的权重变更为 6 。在这次操作之后,从节点 7 到节点 4 的路径中的所有边的权重都是 6 。因此,答案为 3 。 对于每条查询 queries[i] ,可以证明 answer[i] 是使从 ai 到 bi 的路径中的所有边的权重相等的最小操作次数。
提示:
1 <= n <= 104edges.length == n - 1edges[i].length == 30 <= ui, vi < n1 <= wi <= 26- 生成的输入满足
edges表示一棵有效的树 1 <= queries.length == m <= 2 * 104queries[i].length == 20 <= ai, bi < n