标签: 链表
难度: Medium
给你两个链表 list1 和 list2 ,它们包含的元素分别为 n 个和 m 个。
请你将 list1 中下标从 a 到 b 的全部节点都删除,并将list2 接在被删除节点的位置。
下图中蓝色边和节点展示了操作后的结果:
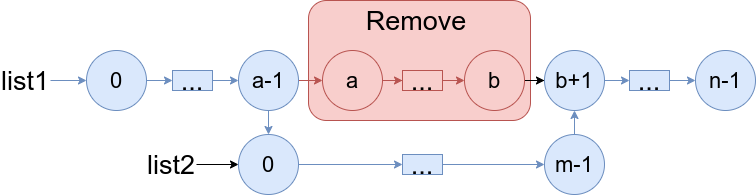
请你返回结果链表的头指针。
示例 1:
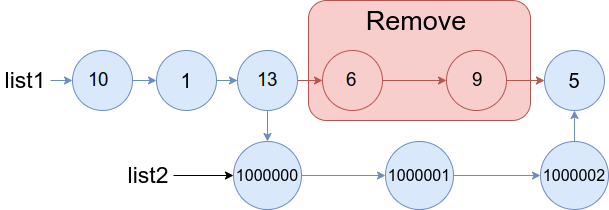
输入:list1 = [10,1,13,6,9,5], a = 3, b = 4, list2 = [1000000,1000001,1000002] 输出:[10,1,13,1000000,1000001,1000002,5] 解释:我们删除 list1 中下标为 3 和 4 的两个节点,并将 list2 接在该位置。上图中蓝色的边和节点为答案链表。
示例 2:
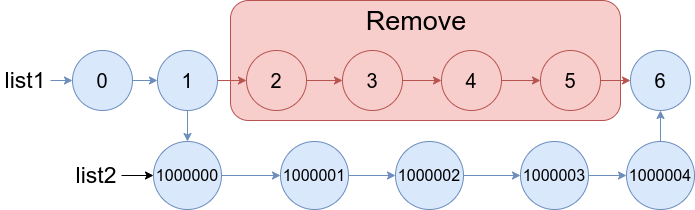
输入:list1 = [0,1,2,3,4,5,6], a = 2, b = 5, list2 = [1000000,1000001,1000002,1000003,1000004] 输出:[0,1,1000000,1000001,1000002,1000003,1000004,6] 解释:上图中蓝色的边和节点为答案链表。
提示:
3 <= list1.length <= 1041 <= a <= b < list1.length - 11 <= list2.length <= 104