难度: Hard
你打算利用空闲时间来做兼职工作赚些零花钱。
这里有 n 份兼职工作,每份工作预计从 startTime[i] 开始到 endTime[i] 结束,报酬为 profit[i]。
给你一份兼职工作表,包含开始时间 startTime,结束时间 endTime 和预计报酬 profit 三个数组,请你计算并返回可以获得的最大报酬。
注意,时间上出现重叠的 2 份工作不能同时进行。
如果你选择的工作在时间 X 结束,那么你可以立刻进行在时间 X 开始的下一份工作。
示例 1:
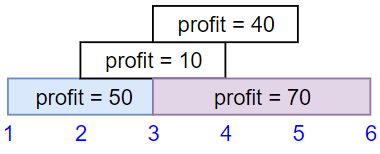
输入:startTime = [1,2,3,3], endTime = [3,4,5,6], profit = [50,10,40,70] 输出:120 解释: 我们选出第 1 份和第 4 份工作, 时间范围是 [1-3]+[3-6],共获得报酬 120 = 50 + 70。
示例 2:
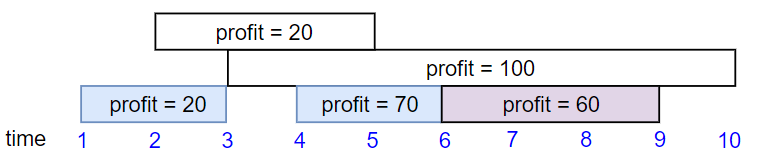
输入:startTime = [1,2,3,4,6], endTime = [3,5,10,6,9], profit = [20,20,100,70,60] 输出:150 解释: 我们选择第 1,4,5 份工作。 共获得报酬 150 = 20 + 70 + 60。
示例 3:

输入:startTime = [1,1,1], endTime = [2,3,4], profit = [5,6,4] 输出:6
提示:
1 <= startTime.length == endTime.length == profit.length <= 5 * 10^41 <= startTime[i] < endTime[i] <= 10^91 <= profit[i] <= 10^4