难度: Medium
给你一棵二叉树,它的根为 root 。请你删除 1 条边,使二叉树分裂成两棵子树,且它们子树和的乘积尽可能大。
由于答案可能会很大,请你将结果对 10^9 + 7 取模后再返回。
示例 1:
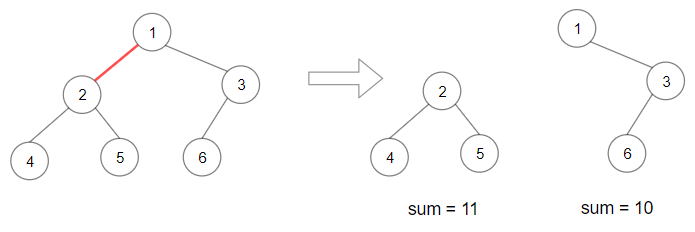
输入:root = [1,2,3,4,5,6] 输出:110 解释:删除红色的边,得到 2 棵子树,和分别为 11 和 10 。它们的乘积是 110 (11*10)
示例 2:
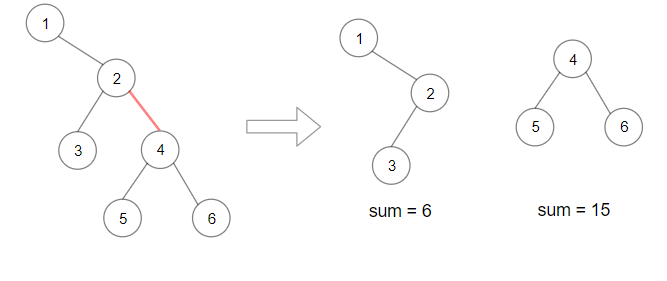
输入:root = [1,null,2,3,4,null,null,5,6] 输出:90 解释:移除红色的边,得到 2 棵子树,和分别是 15 和 6 。它们的乘积为 90 (15*6)
示例 3:
输入:root = [2,3,9,10,7,8,6,5,4,11,1] 输出:1025
示例 4:
输入:root = [1,1] 输出:1
提示:
- 每棵树最多有
50000个节点,且至少有2个节点。 - 每个节点的值在
[1, 10000]之间。