标签: 广度优先搜索 并查集 数组 双指针 矩阵 排序 堆(优先队列)
难度: Hard
给你一个大小为 m x n 的整数矩阵 grid 和一个大小为 k 的数组 queries 。
找出一个大小为 k 的数组 answer ,且满足对于每个整数 queries[i] ,你从矩阵 左上角 单元格开始,重复以下过程:
- 如果
queries[i]严格 大于你当前所处位置单元格,如果该单元格是第一次访问,则获得 1 分,并且你可以移动到所有4个方向(上、下、左、右)上任一 相邻 单元格。 - 否则,你不能获得任何分,并且结束这一过程。
在过程结束后,answer[i] 是你可以获得的最大分数。注意,对于每个查询,你可以访问同一个单元格 多次 。
返回结果数组 answer 。
示例 1:
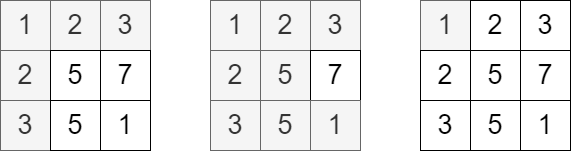
输入:grid = [[1,2,3],[2,5,7],[3,5,1]], queries = [5,6,2] 输出:[5,8,1] 解释:上图展示了每个查询中访问并获得分数的单元格。
示例 2:
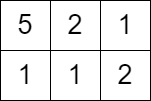
输入:grid = [[5,2,1],[1,1,2]], queries = [3] 输出:[0] 解释:无法获得分数,因为左上角单元格的值大于等于 3 。
提示:
m == grid.lengthn == grid[i].length2 <= m, n <= 10004 <= m * n <= 105k == queries.length1 <= k <= 1041 <= grid[i][j], queries[i] <= 106