难度: Medium
给你一个下标从 0 开始大小为 m x n 的二维整数数组 grid ,其中下标在 (r, c) 处的整数表示:
- 如果
grid[r][c] = 0,那么它是一块 陆地 。 - 如果
grid[r][c] > 0,那么它是一块 水域 ,且包含grid[r][c]条鱼。
一位渔夫可以从任意 水域 格子 (r, c) 出发,然后执行以下操作任意次:
- 捕捞格子
(r, c)处所有的鱼,或者 - 移动到相邻的 水域 格子。
请你返回渔夫最优策略下, 最多 可以捕捞多少条鱼。如果没有水域格子,请你返回 0 。
格子 (r, c) 相邻 的格子为 (r, c + 1) ,(r, c - 1) ,(r + 1, c) 和 (r - 1, c) ,前提是相邻格子在网格图内。
示例 1:
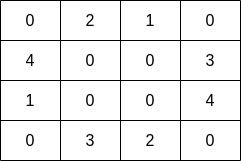
输入:grid = [[0,2,1,0],[4,0,0,3],[1,0,0,4],[0,3,2,0]] 输出:7 解释:渔夫可以从格子(1,3)出发,捕捞 3 条鱼,然后移动到格子(2,3),捕捞 4 条鱼。
示例 2:
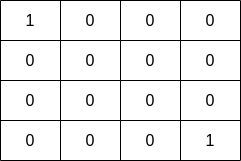
输入:grid = [[1,0,0,0],[0,0,0,0],[0,0,0,0],[0,0,0,1]] 输出:1 解释:渔夫可以从格子 (0,0) 或者 (3,3) ,捕捞 1 条鱼。
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 100 <= grid[i][j] <= 10