难度: Easy
给定一个 N 叉树,找到其最大深度。
最大深度是指从根节点到最远叶子节点的最长路径上的节点总数。
N 叉树输入按层序遍历序列化表示,每组子节点由空值分隔(请参见示例)。
示例 1:
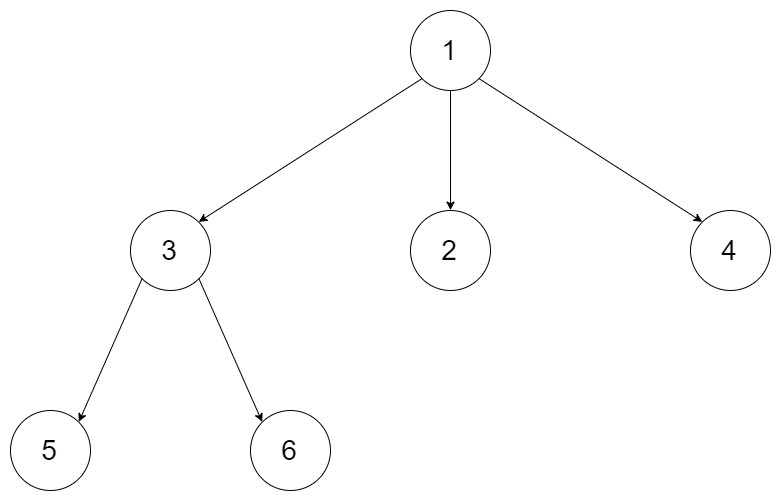
输入:root = [1,null,3,2,4,null,5,6] 输出:3
示例 2:
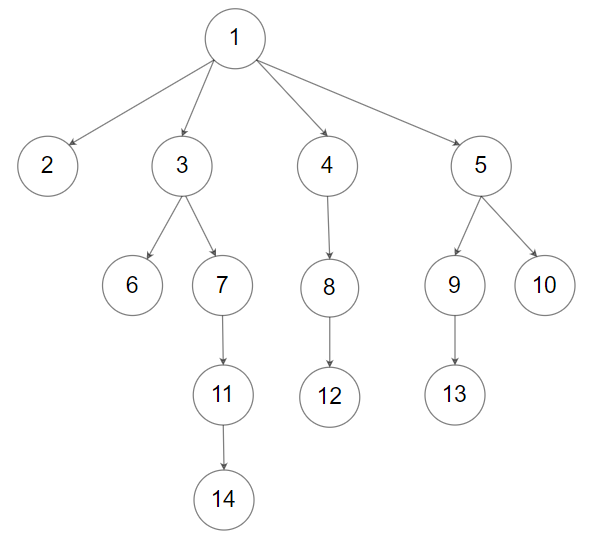
输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14] 输出:5
提示:
- 树的深度不会超过
1000。 - 树的节点数目位于
[0, 104]之间。