难度: Hard
给你一个长度为 n 的字符串 s ,和一个整数 k 。请你找出字符串 s 中 重复 k 次的 最长子序列 。
子序列 是由其他字符串删除某些(或不删除)字符派生而来的一个字符串。
如果 seq * k 是 s 的一个子序列,其中 seq * k 表示一个由 seq 串联 k 次构造的字符串,那么就称 seq 是字符串 s 中一个 重复 k 次 的子序列。
- 举个例子,
"bba"是字符串"bababcba"中的一个重复2次的子序列,因为字符串"bbabba"是由"bba"串联2次构造的,而"bbabba"是字符串"bababcba"的一个子序列。
返回字符串 s 中 重复 k 次的最长子序列 。如果存在多个满足的子序列,则返回 字典序最大 的那个。如果不存在这样的子序列,返回一个 空 字符串。
示例 1:
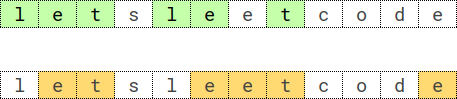
输入:s = "letsleetcode", k = 2 输出:"let" 解释:存在两个最长子序列重复 2 次:let" 和 "ete" 。 "let" 是其中字典序最大的一个。
示例 2:
输入:s = "bb", k = 2 输出:"b" 解释:重复 2 次的最长子序列是 "b" 。
示例 3:
输入:s = "ab", k = 2 输出:"" 解释:不存在重复 2 次的最长子序列。返回空字符串。
提示:
n == s.length2 <= k <= 20002 <= n < k * 8s由小写英文字母组成