难度: Medium
二进制矩阵中的所有元素不是 0 就是 1 。
给你两个四叉树,quadTree1 和 quadTree2。其中 quadTree1 表示一个 n * n 二进制矩阵,而 quadTree2 表示另一个 n * n 二进制矩阵。
请你返回一个表示 n * n 二进制矩阵的四叉树,它是 quadTree1 和 quadTree2 所表示的两个二进制矩阵进行 按位逻辑或运算 的结果。
注意,当 isLeaf 为 False 时,你可以把 True 或者 False 赋值给节点,两种值都会被判题机制 接受 。
四叉树数据结构中,每个内部节点只有四个子节点。此外,每个节点都有两个属性:
val:储存叶子结点所代表的区域的值。1 对应 True,0 对应 False;isLeaf: 当这个节点是一个叶子结点时为 True,如果它有 4 个子节点则为 False 。
class Node {
public boolean val;
public boolean isLeaf;
public Node topLeft;
public Node topRight;
public Node bottomLeft;
public Node bottomRight;
}
我们可以按以下步骤为二维区域构建四叉树:
- 如果当前网格的值相同(即,全为
0或者全为1),将isLeaf设为 True ,将val设为网格相应的值,并将四个子节点都设为 Null 然后停止。 - 如果当前网格的值不同,将
isLeaf设为 False, 将val设为任意值,然后如下图所示,将当前网格划分为四个子网格。 - 使用适当的子网格递归每个子节点。
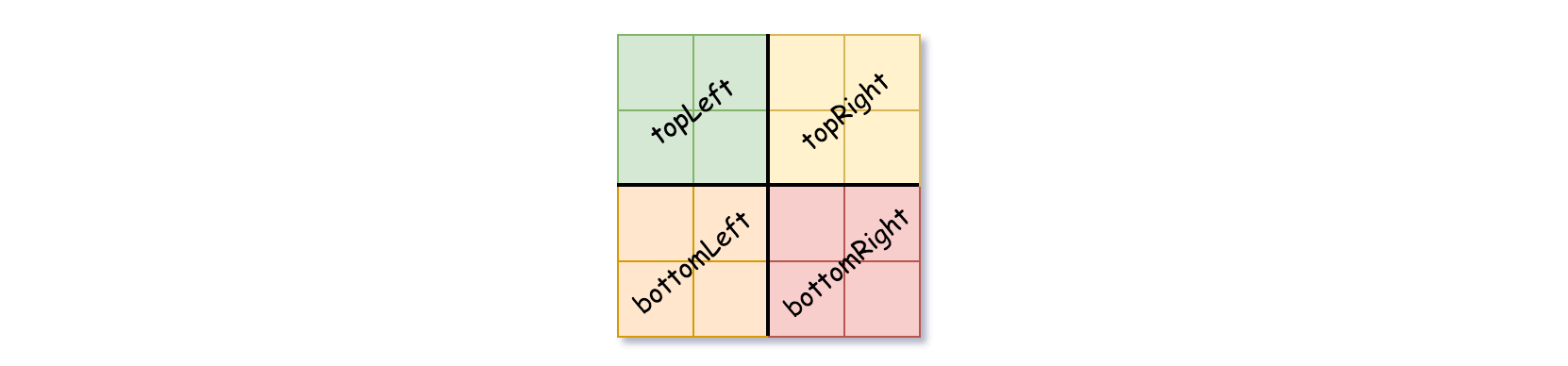
如果你想了解更多关于四叉树的内容,可以参考 wiki 。
四叉树格式:
输出为使用层序遍历后四叉树的序列化形式,其中 null 表示路径终止符,其下面不存在节点。
它与二叉树的序列化非常相似。唯一的区别是节点以列表形式表示 [isLeaf, val] 。
如果 isLeaf 或者 val 的值为 True ,则表示它在列表 [isLeaf, val] 中的值为 1 ;如果 isLeaf 或者 val 的值为 False ,则表示值为 0 。
示例 1:
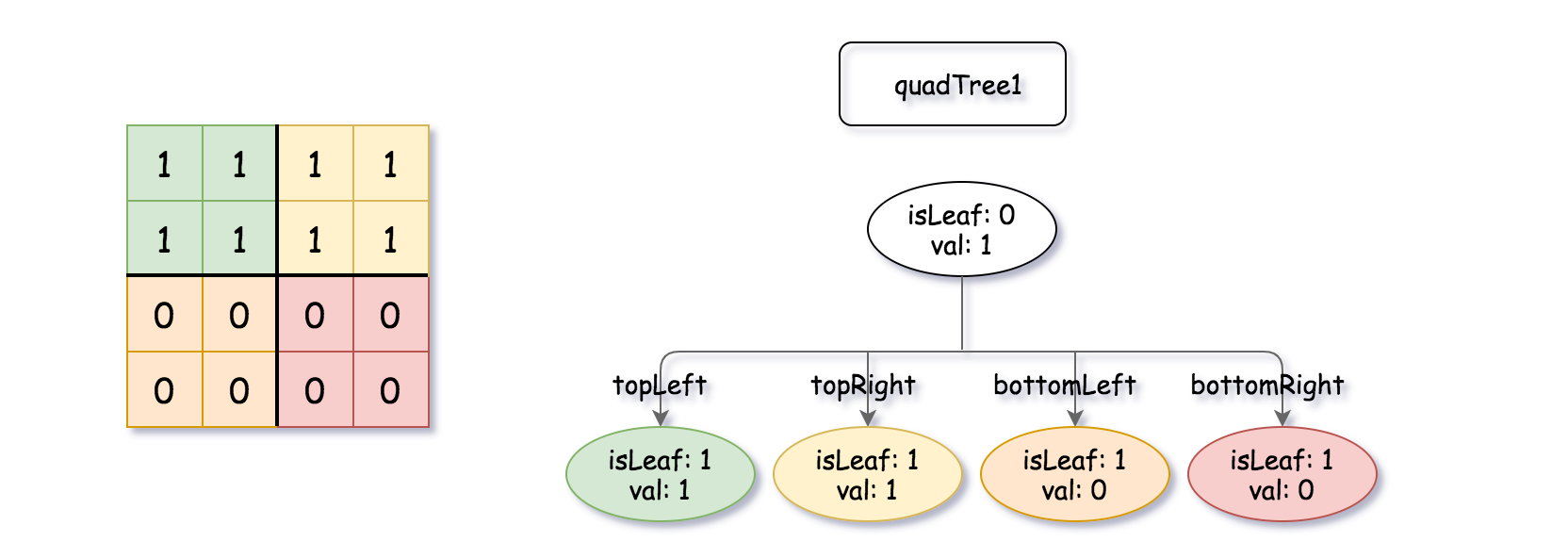
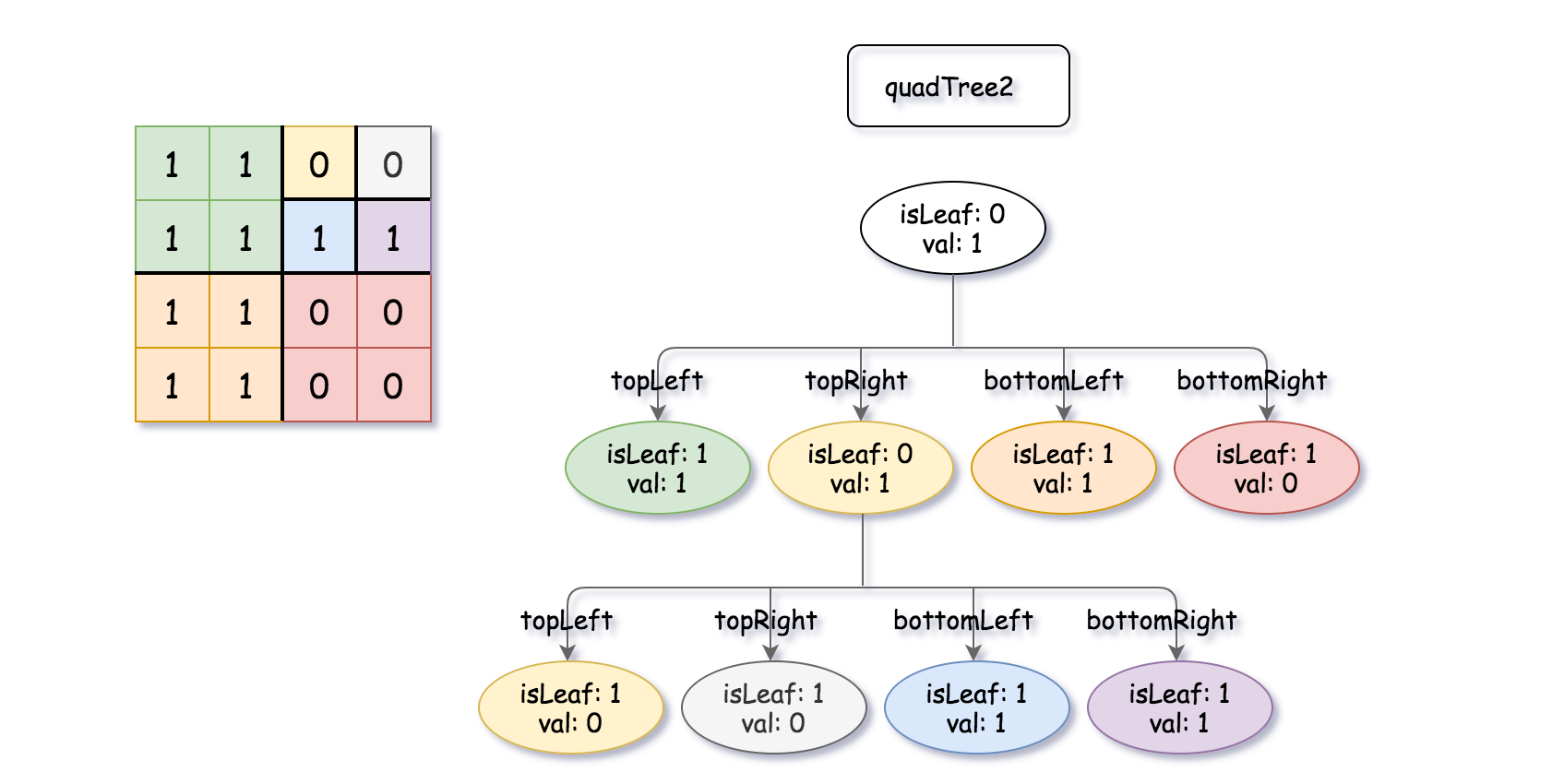
输入:quadTree1 = [[0,1],[1,1],[1,1],[1,0],[1,0]] , quadTree2 = [[0,1],[1,1],[0,1],[1,1],[1,0],null,null,null,null,[1,0],[1,0],[1,1],[1,1]] 输出:[[0,0],[1,1],[1,1],[1,1],[1,0]] 解释:quadTree1 和 quadTree2 如上所示。由四叉树所表示的二进制矩阵也已经给出。 如果我们对这两个矩阵进行按位逻辑或运算,则可以得到下面的二进制矩阵,由一个作为结果的四叉树表示。 注意,我们展示的二进制矩阵仅仅是为了更好地说明题意,你无需构造二进制矩阵来获得结果四叉树。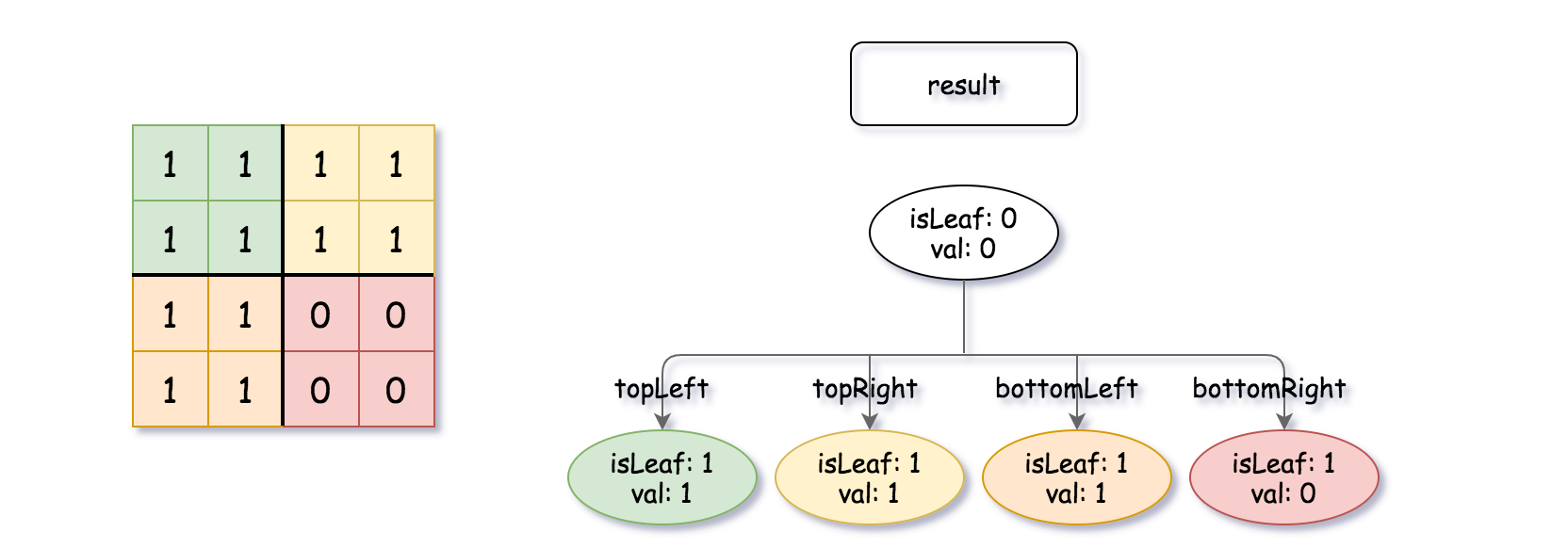
示例 2:
输入:quadTree1 = [[1,0]] , quadTree2 = [[1,0]] 输出:[[1,0]] 解释:两个数所表示的矩阵大小都为 1*1,值全为 0 结果矩阵大小为 1*1,值全为 0 。
示例 3:
输入:quadTree1 = [[0,0],[1,0],[1,0],[1,1],[1,1]] , quadTree2 = [[0,0],[1,1],[1,1],[1,0],[1,1]] 输出:[[1,1]]
示例 4:
输入:quadTree1 = [[0,0],[1,1],[1,0],[1,1],[1,1]] , quadTree2 = [[0,0],[1,1],[0,1],[1,1],[1,1],null,null,null,null,[1,1],[1,0],[1,0],[1,1]] 输出:[[0,0],[1,1],[0,1],[1,1],[1,1],null,null,null,null,[1,1],[1,0],[1,0],[1,1]]
示例 5:
输入:quadTree1 = [[0,1],[1,0],[0,1],[1,1],[1,0],null,null,null,null,[1,0],[1,0],[1,1],[1,1]] , quadTree2 = [[0,1],[0,1],[1,0],[1,1],[1,0],[1,0],[1,0],[1,1],[1,1]] 输出:[[0,0],[0,1],[0,1],[1,1],[1,0],[1,0],[1,0],[1,1],[1,1],[1,0],[1,0],[1,1],[1,1]]
提示:
quadTree1和quadTree2都是符合题目要求的四叉树,每个都代表一个n * n的矩阵。n == 2^x,其中0 <= x <= 9.