标签: 深度优先搜索 广度优先搜索 并查集 数组 二分查找 矩阵
难度: Hard
给你一个下标从 1 开始的二进制矩阵,其中 0 表示陆地,1 表示水域。同时给你 row 和 col 分别表示矩阵中行和列的数目。
一开始在第 0 天,整个 矩阵都是 陆地 。但每一天都会有一块新陆地被 水 淹没变成水域。给你一个下标从 1 开始的二维数组 cells ,其中 cells[i] = [ri, ci] 表示在第 i 天,第 ri 行 ci 列(下标都是从 1 开始)的陆地会变成 水域 (也就是 0 变成 1 )。
你想知道从矩阵最 上面 一行走到最 下面 一行,且只经过陆地格子的 最后一天 是哪一天。你可以从最上面一行的 任意 格子出发,到达最下面一行的 任意 格子。你只能沿着 四个 基本方向移动(也就是上下左右)。
请返回只经过陆地格子能从最 上面 一行走到最 下面 一行的 最后一天 。
示例 1:
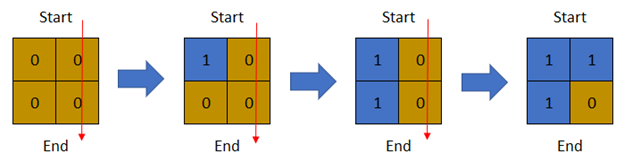
输入:row = 2, col = 2, cells = [[1,1],[2,1],[1,2],[2,2]] 输出:2 解释:上图描述了矩阵从第 0 天开始是如何变化的。 可以从最上面一行到最下面一行的最后一天是第 2 天。
示例 2:
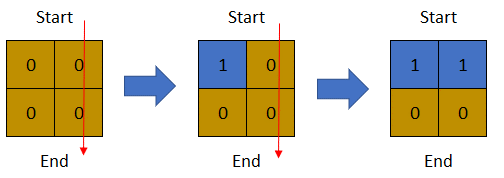
输入:row = 2, col = 2, cells = [[1,1],[1,2],[2,1],[2,2]] 输出:1 解释:上图描述了矩阵从第 0 天开始是如何变化的。 可以从最上面一行到最下面一行的最后一天是第 1 天。
示例 3:
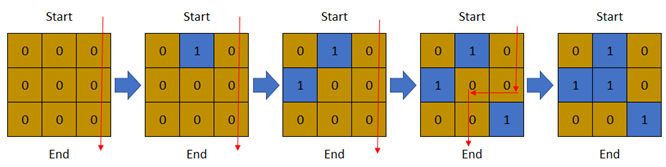
输入:row = 3, col = 3, cells = [[1,2],[2,1],[3,3],[2,2],[1,1],[1,3],[2,3],[3,2],[3,1]] 输出:3 解释:上图描述了矩阵从第 0 天开始是如何变化的。 可以从最上面一行到最下面一行的最后一天是第 3 天。
提示:
2 <= row, col <= 2 * 1044 <= row * col <= 2 * 104cells.length == row * col1 <= ri <= row1 <= ci <= colcells中的所有格子坐标都是 唯一 的。