难度: Hard
给你一棵 二叉树 的根节点 root ,树中有 n 个节点。每个节点都可以被分配一个从 1 到 n 且互不相同的值。另给你一个长度为 m 的数组 queries 。
你必须在树上执行 m 个 独立 的查询,其中第 i 个查询你需要执行以下操作:
- 从树中 移除 以
queries[i]的值作为根节点的子树。题目所用测试用例保证queries[i]不 等于根节点的值。
返回一个长度为 m 的数组 answer ,其中 answer[i] 是执行第 i 个查询后树的高度。
注意:
- 查询之间是独立的,所以在每个查询执行后,树会回到其 初始 状态。
- 树的高度是从根到树中某个节点的 最长简单路径中的边数 。
示例 1:
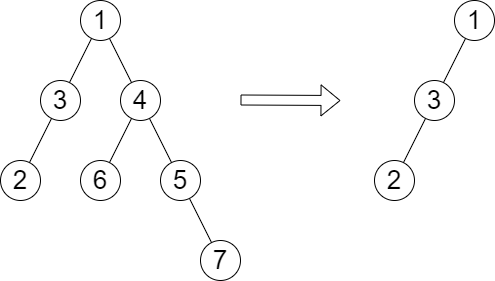
输入:root = [1,3,4,2,null,6,5,null,null,null,null,null,7], queries = [4] 输出:[2] 解释:上图展示了从树中移除以 4 为根节点的子树。 树的高度是 2(路径为 1 -> 3 -> 2)。
示例 2:
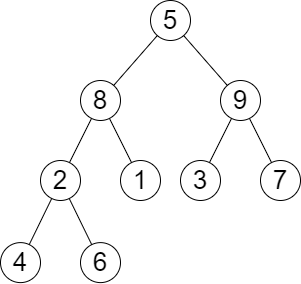
输入:root = [5,8,9,2,1,3,7,4,6], queries = [3,2,4,8] 输出:[3,2,3,2] 解释:执行下述查询: - 移除以 3 为根节点的子树。树的高度变为 3(路径为 5 -> 8 -> 2 -> 4)。 - 移除以 2 为根节点的子树。树的高度变为 2(路径为 5 -> 8 -> 1)。 - 移除以 4 为根节点的子树。树的高度变为 3(路径为 5 -> 8 -> 2 -> 6)。 - 移除以 8 为根节点的子树。树的高度变为 2(路径为 5 -> 9 -> 3)。
提示:
- 树中节点的数目是
n 2 <= n <= 1051 <= Node.val <= n- 树中的所有值 互不相同
m == queries.length1 <= m <= min(n, 104)1 <= queries[i] <= nqueries[i] != root.val