难度: Medium
有 n 个人,每个人都有一个 0 到 n-1 的唯一 id 。
给你数组 watchedVideos 和 friends ,其中 watchedVideos[i] 和 friends[i] 分别表示 id = i 的人观看过的视频列表和他的好友列表。
Level 1 的视频包含所有你好友观看过的视频,level 2 的视频包含所有你好友的好友观看过的视频,以此类推。一般的,Level 为 k 的视频包含所有从你出发,最短距离为 k 的好友观看过的视频。
给定你的 id 和一个 level 值,请你找出所有指定 level 的视频,并将它们按观看频率升序返回。如果有频率相同的视频,请将它们按字母顺序从小到大排列。
示例 1:
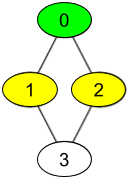
输入:watchedVideos = [["A","B"],["C"],["B","C"],["D"]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 1 输出:["B","C"] 解释: 你的 id 为 0(绿色),你的朋友包括(黄色): id 为 1 -> watchedVideos = ["C"] id 为 2 -> watchedVideos = ["B","C"] 你朋友观看过视频的频率为: B -> 1 C -> 2
示例 2:
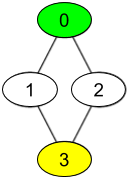
输入:watchedVideos = [["A","B"],["C"],["B","C"],["D"]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 2 输出:["D"] 解释: 你的 id 为 0(绿色),你朋友的朋友只有一个人,他的 id 为 3(黄色)。
提示:
n == watchedVideos.length == friends.length2 <= n <= 1001 <= watchedVideos[i].length <= 1001 <= watchedVideos[i][j].length <= 80 <= friends[i].length < n0 <= friends[i][j] < n0 <= id < n1 <= level < n- 如果
friends[i]包含j,那么friends[j]包含i