难度: Medium
你会得到一个双链表,其中包含的节点有一个下一个指针、一个前一个指针和一个额外的 子指针 。这个子指针可能指向一个单独的双向链表,也包含这些特殊的节点。这些子列表可以有一个或多个自己的子列表,以此类推,以生成如下面的示例所示的 多层数据结构 。
给定链表的头节点 head ,将链表 扁平化 ,以便所有节点都出现在单层双链表中。让 curr 是一个带有子列表的节点。子列表中的节点应该出现在扁平化列表中的 curr 之后 和 curr.next 之前 。
返回 扁平列表的 head 。列表中的节点必须将其 所有 子指针设置为 null 。
示例 1:
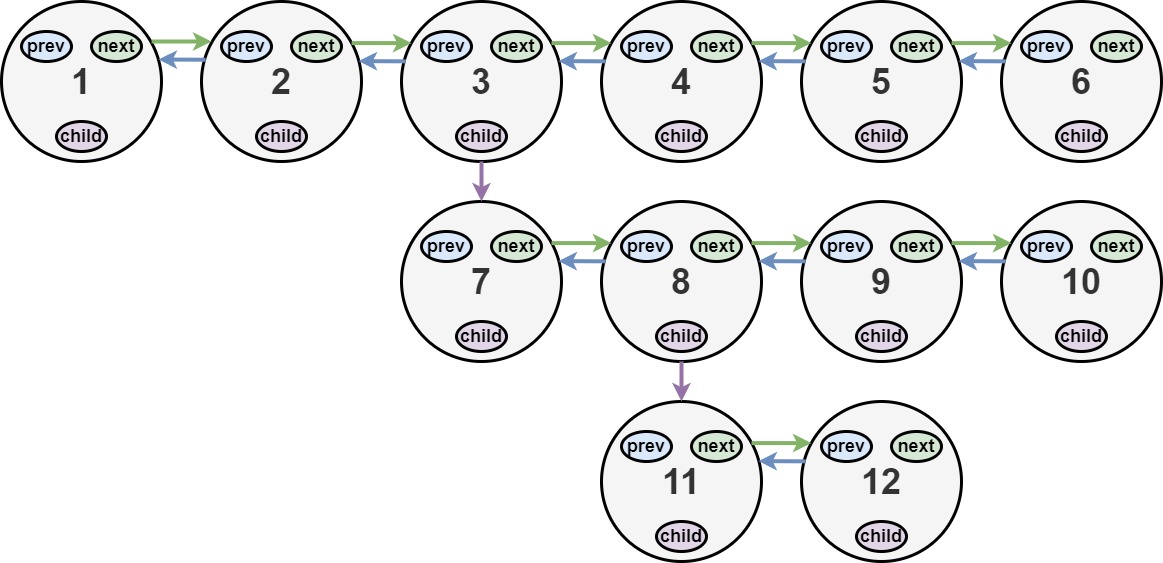
输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12] 输出:[1,2,3,7,8,11,12,9,10,4,5,6] 解释:输入的多级列表如上图所示。 扁平化后的链表如下图:
示例 2:

输入:head = [1,2,null,3] 输出:[1,3,2] 解释:输入的多级列表如上图所示。 扁平化后的链表如下图: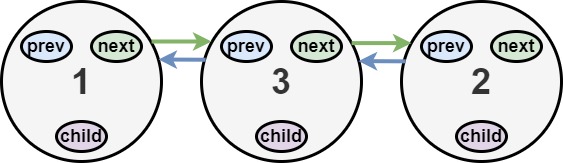
示例 3:
输入:head = [] 输出:[] 说明:输入中可能存在空列表。
提示:
- 节点数目不超过
1000 1 <= Node.val <= 105
如何表示测试用例中的多级链表?
以 示例 1 为例:
1---2---3---4---5---6--NULL
|
7---8---9---10--NULL
|
11--12--NULL
序列化其中的每一级之后:
[1,2,3,4,5,6,null] [7,8,9,10,null] [11,12,null]
为了将每一级都序列化到一起,我们需要每一级中添加值为 null 的元素,以表示没有节点连接到上一级的上级节点。
[1,2,3,4,5,6,null] [null,null,7,8,9,10,null] [null,11,12,null]
合并所有序列化结果,并去除末尾的 null 。
[1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]