难度: Medium
给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。
示例1:
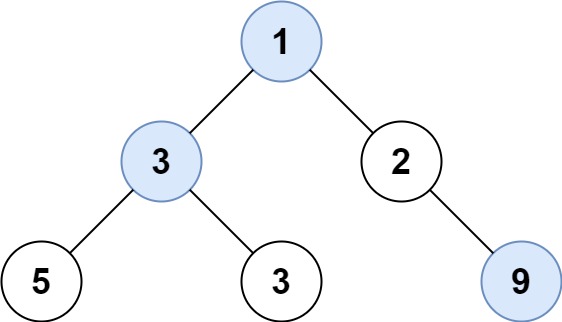
输入: root = [1,3,2,5,3,null,9] 输出: [1,3,9]
示例2:
输入: root = [1,2,3] 输出: [1,3]
提示:
- 二叉树的节点个数的范围是
[0,104] -231 <= Node.val <= 231 - 1
难度: Medium
给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。
示例1:
输入: root = [1,3,2,5,3,null,9] 输出: [1,3,9]
示例2:
输入: root = [1,2,3] 输出: [1,3]
提示:
[0,104]-231 <= Node.val <= 231 - 1运行时间: 24 ms
内存: 18.8 MB
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def largestValues(self, root: Optional[TreeNode]) -> List[int]:
ans = list()
def dfs(root,h):
if root:
if h >= len(ans):
ans.append(root.val)
else:
ans[h] = max(ans[h],root.val)
dfs(root.left,h+1)
dfs(root.right,h+1)
dfs(root,0)
return ans
这个题解采用深度优先搜索(DFS)的思路。它从根节点开始递归地遍历整棵树,同时跟踪当前节点所在的层高(h)。在每个递归步骤中,如果当前层高大于等于结果列表 ans 的长度,就将当前节点的值加入 ans。否则,比较当前节点的值与 ans 中对应层高的最大值,取较大者更新 ans。然后递归地处理当前节点的左右子树,层高 h 加 1。最后返回 ans,即每一层的最大值列表。
时间复杂度: O(n)
空间复杂度: O(n)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def largestValues(self, root: Optional[TreeNode]) -> List[int]:
ans = list()
def dfs(root, h):
if root:
# 如果当前层高大于等于结果列表长度,添加当前节点值
if h >= len(ans):
ans.append(root.val)
# 否则更新当前层的最大值
else:
ans[h] = max(ans[h], root.val)
# 递归处理左子树,层高加一
dfs(root.left, h+1)
# 递归处理右子树,层高加一
dfs(root.right, h+1)
# 从根节点开始DFS,初始层高为0
dfs(root, 0)
return ans
在题解中提供的DFS递归逻辑里,递归函数`dfs`是从根节点开始调用,并在函数内部检查`if root:`来判断当前节点是否为null。如果`root`为null,则当前递归调用不会执行任何操作,直接返回,因此不会有null值的节点被处理或导致错误。这种方式有效地避免了null节点引起的问题。
虽然ans[h]可能已经记录了之前访问过的节点中的最大值,但是在继续DFS过程中,我们仍然需要考虑当前层后续节点的值可能更大的情况。因此,每次访问一个新节点时,都需要将其值与ans[h]进行比较,并在必要时更新ans[h],以确保能够正确地记录每一层的最大值。这是确保结果正确性的必要步骤。
题解中的DFS递归的终止条件是当前访问的节点为null,即在递归函数`dfs`的开始通过`if root:`判断来实现。如果节点为null,递归不再继续向下执行。此外,每个节点仅被访问一次是通过递归调用的机制保证的,即每个节点在递归中只会被处理一次,分别在其左右子节点之后。这样的调用顺序确保了每个节点只被访问一次。
在这个特定的问题中,使用列表来记录每一层的最大值是因为每层的索引(层高h)是一个从0开始的连续整数,这使得列表成为一个非常适合的选择,因为可以直接使用层高作为索引进行访问和更新操作。列表相比字典在这种情况下有更好的空间和时间效率,因为它直接支持按索引访问,而不需要额外的键查找开销。