标签: 树 深度优先搜索 广度优先搜索 设计 哈希表 二叉树
难度: Medium
给出一个满足下述规则的二叉树:
root.val == 0- 如果
treeNode.val == x且treeNode.left != null,那么treeNode.left.val == 2 * x + 1 - 如果
treeNode.val == x且treeNode.right != null,那么treeNode.right.val == 2 * x + 2
现在这个二叉树受到「污染」,所有的 treeNode.val 都变成了 -1。
请你先还原二叉树,然后实现 FindElements 类:
FindElements(TreeNode* root)用受污染的二叉树初始化对象,你需要先把它还原。bool find(int target)判断目标值target是否存在于还原后的二叉树中并返回结果。
示例 1:
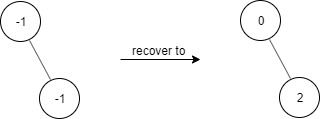
输入: ["FindElements","find","find"] [[[-1,null,-1]],[1],[2]] 输出: [null,false,true] 解释: FindElements findElements = new FindElements([-1,null,-1]); findElements.find(1); // return False findElements.find(2); // return True
示例 2:
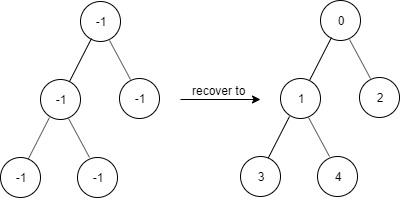
输入: ["FindElements","find","find","find"] [[[-1,-1,-1,-1,-1]],[1],[3],[5]] 输出: [null,true,true,false] 解释: FindElements findElements = new FindElements([-1,-1,-1,-1,-1]); findElements.find(1); // return True findElements.find(3); // return True findElements.find(5); // return False
示例 3:
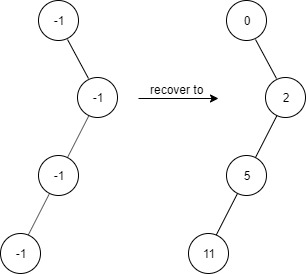
输入: ["FindElements","find","find","find","find"] [[[-1,null,-1,-1,null,-1]],[2],[3],[4],[5]] 输出: [null,true,false,false,true] 解释: FindElements findElements = new FindElements([-1,null,-1,-1,null,-1]); findElements.find(2); // return True findElements.find(3); // return False findElements.find(4); // return False findElements.find(5); // return True
提示:
TreeNode.val == -1- 二叉树的高度不超过
20 - 节点的总数在
[1, 10^4]之间 - 调用
find()的总次数在[1, 10^4]之间 0 <= target <= 10^6