难度: Medium
给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。
假设二叉树中至少有一个节点。
示例 1:
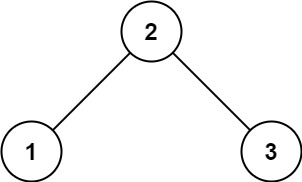
输入: root = [2,1,3] 输出: 1
示例 2:
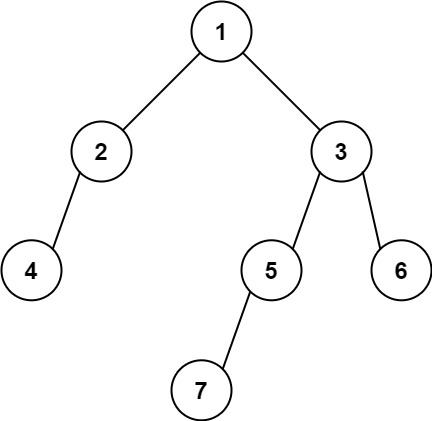
输入: [1,2,3,4,null,5,6,null,null,7] 输出: 7
提示:
- 二叉树的节点个数的范围是
[1,104] -231 <= Node.val <= 231 - 1
难度: Medium
给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。
假设二叉树中至少有一个节点。
示例 1:
输入: root = [2,1,3] 输出: 1
示例 2:
输入: [1,2,3,4,null,5,6,null,null,7] 输出: 7
提示:
[1,104]-231 <= Node.val <= 231 - 1 运行时间: 23 ms
内存: 18.1 MB
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def findBottomLeftValue(self, root: Optional[TreeNode]) -> int:
'''
先理解:
先最底层 然后最左边;
到达最底下了;在考虑左右
解法一:
遍历到最后一层的; 第一个节点输出
解法二:
从右到左 , 遍历入队; 然后最左边先出队后;最后一个为
记得进队顺序; 先把右儿子进; 然后左儿子进
'''
# if root is None:
# return None
# p = deque([root])
# while p :
# node = p.popleft() #让最左边的先出去;那么考虑先将右子树放入,再将左子树放入;这样最左边就会最后出去
# if node.right: #先让 右儿子进
# p.append(node.right)
# if node.left: # 再让左子树值,存入队列;
# p.append(node.left)
# return node.val #进队 出队完后; 最后一个出队的就是找的
q = deque([root]) # 反过来,那么正常顺序入队,先左后右,那么最右边的先出;这样会疏忽最底层,错误想法
while q :
node = q.popleft()
if node.right: q.append(node.right)
if node.left: q.append(node.left)
return node.val
这个题解采用了广度优先搜索(BFS)的方法。具体思路如下: 1. 使用一个队列存储节点,初始时将根节点加入队列。 2. 不断从队列中取出节点,直到队列为空。 3. 在每次取出节点时,先将右子节点加入队列,再将左子节点加入队列。这样可以确保最后一个加入队列的节点就是最底层最左边的节点。 4. 当队列为空时,最后一个被取出的节点就是所求的最底层最左边的节点,返回其值即可。
时间复杂度: O(n)
空间复杂度: O(n)
class Solution:
def findBottomLeftValue(self, root: Optional[TreeNode]) -> int:
q = deque([root])
while q:
node = q.popleft()
# 先将右子节点加入队列
if node.right:
q.append(node.right)
# 再将左子节点加入队列
if node.left:
q.append(node.left)
# 最后一个被取出的节点即为所求
return node.val
在广度优先搜索中,通常节点是从左到右加入队列的。然而,这个题解中故意先加右子节点再加左子节点,是为了确保在每一层中,最左边的节点最后被加入队列。因为队列是先进先出的结构,这样操作保证了最后处理的层是最底层,而层中最后被访问的节点就是最左边的节点。这种逆序加入的方式简化了找到最底层最左边节点的逻辑,使得无需记录额外的层级信息。
如果二叉树极度不平衡,比如形成了一个链状结构,不论是向左倾斜还是向右倾斜,算法仍能正确运行。在这种情况下,算法的时间复杂度和空间复杂度都变为O(n),其中n是节点数。因为每个节点仍然需要被访问一次,并加入队列中。不过,队列的最大长度将减少,因为每次只有一个节点在队列中。
确实,这个算法要求所有节点至少一次被存储在队列中,这意味着空间复杂度为O(n),n为树中的节点总数。内存优化方面,可以考虑使用更高效的数据结构来存储队列中的节点。例如,使用链表而非数组可以避免数组动态扩容带来的额外内存消耗。然而,总体而言,至少需要一次性存储所有访问过的节点,以保证算法的运作。
二叉树节点的值大小不会直接影响算法的时间或空间复杂度,因为算法的复杂度主要由树的结构(即节点数和树的深度)决定。不过,如果节点值的数据类型超过了常规整数的存储范围,可能需要使用更大范围的数据类型(如Python的长整型),这可能会增加单个节点值存储的内存需求。然而,这种情况对现代计算系统而言通常不是问题。