难度: Easy
有 n 个 (id, value) 对,其中 id 是 1 到 n 之间的一个整数,value 是一个字符串。不存在 id 相同的两个 (id, value) 对。
设计一个流,以 任意 顺序获取 n 个 (id, value) 对,并在多次调用时 按 id 递增的顺序 返回一些值。
实现 OrderedStream 类:
OrderedStream(int n)构造一个能接收n个值的流,并将当前指针ptr设为1。String[] insert(int id, String value)向流中存储新的(id, value)对。存储后:- 如果流存储有
id = ptr的(id, value)对,则找出从id = ptr开始的 最长 id 连续递增序列 ,并 按顺序 返回与这些 id 关联的值的列表。然后,将ptr更新为最后那个id + 1。 -
否则,返回一个空列表。
- 如果流存储有
示例:
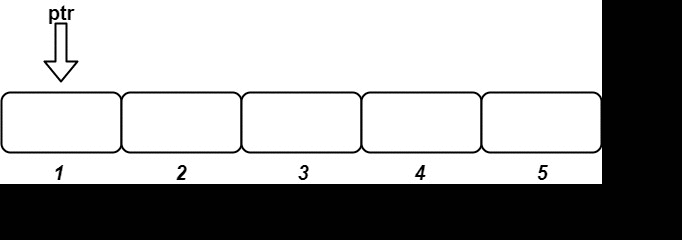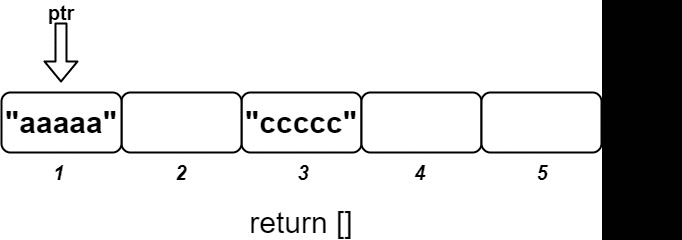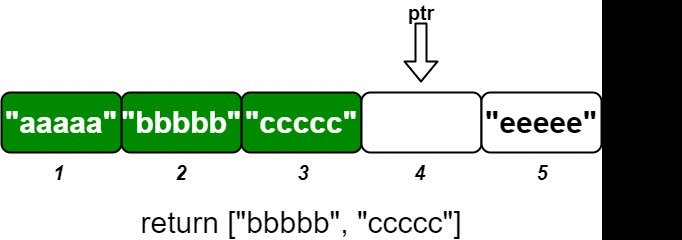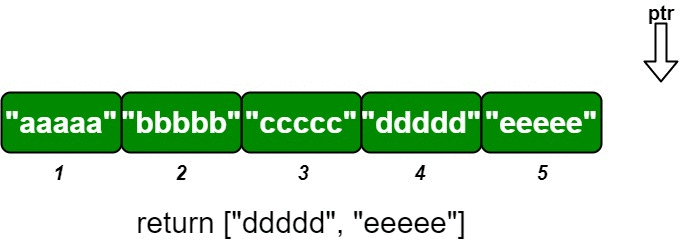
输入 ["OrderedStream", "insert", "insert", "insert", "insert", "insert"] [[5], [3, "ccccc"], [1, "aaaaa"], [2, "bbbbb"], [5, "eeeee"], [4, "ddddd"]] 输出 [null, [], ["aaaaa"], ["bbbbb", "ccccc"], [], ["ddddd", "eeeee"]] 解释 OrderedStream os= new OrderedStream(5); os.insert(3, "ccccc"); // 插入 (3, "ccccc"),返回 [] os.insert(1, "aaaaa"); // 插入 (1, "aaaaa"),返回 ["aaaaa"] os.insert(2, "bbbbb"); // 插入 (2, "bbbbb"),返回 ["bbbbb", "ccccc"] os.insert(5, "eeeee"); // 插入 (5, "eeeee"),返回 [] os.insert(4, "ddddd"); // 插入 (4, "ddddd"),返回 ["ddddd", "eeeee"]
提示:
1 <= n <= 10001 <= id <= nvalue.length == 5value仅由小写字母组成- 每次调用
insert都会使用一个唯一的id - 恰好调用
n次insert