难度: Medium
给你一棵二叉树的根节点 root ,请你返回 层数最深的叶子节点的和 。
示例 1:
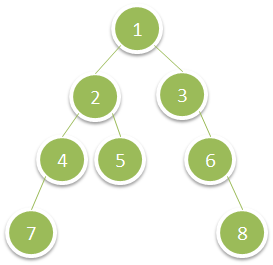
输入:root = [1,2,3,4,5,null,6,7,null,null,null,null,8] 输出:15
示例 2:
输入:root = [6,7,8,2,7,1,3,9,null,1,4,null,null,null,5] 输出:19
提示:
- 树中节点数目在范围
[1, 104]之间。 1 <= Node.val <= 100
难度: Medium
给你一棵二叉树的根节点 root ,请你返回 层数最深的叶子节点的和 。
示例 1:
输入:root = [1,2,3,4,5,null,6,7,null,null,null,null,8] 输出:15
示例 2:
输入:root = [6,7,8,2,7,1,3,9,null,1,4,null,null,null,5] 输出:19
提示:
[1, 104] 之间。1 <= Node.val <= 100运行时间: 91 ms
内存: 19.0 MB
from collections import deque
class Solution:
def deepestLeavesSum(self, root: Optional[TreeNode]) -> int:
if not root:
return 0
queue = deque([root]) # 用于BFS的队列
deepest_sum = 0 # 最深层叶子节点的和
while queue:
level_size = len(queue)
level_sum = 0 # 当前层的叶子节点和
for _ in range(level_size):
node = queue.popleft()
level_sum += node.val
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
# 更新最深层叶子节点的和
deepest_sum = level_sum
return deepest_sum
# 创建二叉树示例
root = TreeNode(1)
root.left = TreeNode(2)
root.right = TreeNode(3)
root.left.left = TreeNode(4)
root.left.right = TreeNode(5)
root.right.right = TreeNode(6)
root.left.left.left = TreeNode(7)
root.left.left.right = TreeNode(8)
# 计算最深层叶子节点的和
solution = Solution()
result = solution.deepestLeavesSum(root)
print(result) # 输出: 15
题解采用了宽度优先搜索(BFS)的方法。通过一个队列来遍历二叉树的每一层。对于每一层,计算其所有节点的值的和,并更新最深层叶子节点的和。当遍历完成时,最后一层即为最深层,其节点和即为所求。
时间复杂度: O(n)
空间复杂度: O(n)
from collections import deque
class Solution:
def deepestLeavesSum(self, root: Optional[TreeNode]) -> int:
if not root:
return 0
queue = deque([root]) # 用于BFS的队列
deepest_sum = 0 # 最深层叶子节点的和
while queue:
level_size = len(queue)
level_sum = 0 # 当前层的叶子节点和
for _ in range(level_size):
node = queue.popleft()
level_sum += node.val
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
# 更新最深层叶子节点的和
deepest_sum = level_sum
return deepest_sum
# 创建二叉树示例
root = TreeNode(1)
root.left = TreeNode(2)
root.right = TreeNode(3)
root.left.left = TreeNode(4)
root.left.right = TreeNode(5)
root.right.right = TreeNode(6)
root.left.left.left = TreeNode(7)
root.left.left.right = TreeNode(8)
# 计算最深层叶子节点的和
solution = Solution()
result = solution.deepestLeavesSum(root)
print(result) # 输出: 15
宽度优先搜索(BFS)通过使用队列来管理节点的遍历顺序,确保按层次顺序访问每个节点。在算法中,只有当队列为空时,BFS才会停止。因为队列初始化时包含根节点,且在遍历过程中,只要节点有子节点就会被添加到队列中,这确保了只有在访问完所有层次后(即队列被清空时),BFS才会结束。因此,BFS能够保证在访问到树的最底层叶子节点之后才停止,不会提前结束。
在宽度优先搜索中使用队列是因为队列遵循先进先出(FIFO)原则,这对于层次遍历是必要的,以便按照从上到下、从左到右的顺序处理节点。如果使用栈(后进先出),则会变成深度优先搜索,改变遍历的顺序。使用堆(通常用于优先队列)在此场景中不适用,因为堆是根据元素优先级进行排序,而不是按插入顺序,这同样会破坏层次遍历的顺序。
在算法中,`level_sum`变量在每一层的开始时重置为0是为了单独计算每一层的节点值总和。这是因为我们需要找到最深层叶子节点的和,而这个和只与最后一层的节点相关。如果不重置`level_sum`,则它会累加所有层的节点值,这不仅会增加计算复杂性,还会导致结果错误,因为我们只需要最深层的节点和。因此,不重置`level_sum`将无法得到正确的最终结果。
在这个特定的算法实现中,我们并不是在每一层结束时判断该层是否为最深层,而是通过更新`deepest_sum`变量的值为当前层`level_sum`的值来处理。由于BFS总是从上到下遍历树的每一层,最后一次更新`deepest_sum`的操作实际上是在最底层进行的。因此,当队列为空,BFS结束时,`deepest_sum`保存的即是最深层叶子节点的和。