标签: 树 深度优先搜索 广度优先搜索 数组 哈希表 二叉树
难度: Medium
给你一个二维整数数组 descriptions ,其中 descriptions[i] = [parenti, childi, isLefti] 表示 parenti 是 childi 在 二叉树 中的 父节点,二叉树中各节点的值 互不相同 。此外:
- 如果
isLefti == 1,那么childi就是parenti的左子节点。 - 如果
isLefti == 0,那么childi就是parenti的右子节点。
请你根据 descriptions 的描述来构造二叉树并返回其 根节点 。
测试用例会保证可以构造出 有效 的二叉树。
示例 1:
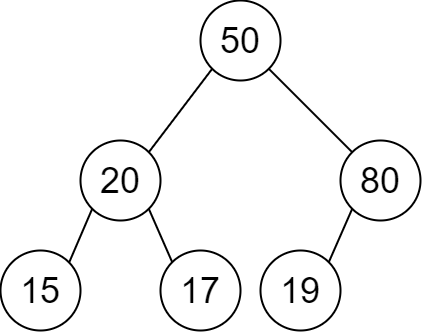
输入:descriptions = [[20,15,1],[20,17,0],[50,20,1],[50,80,0],[80,19,1]] 输出:[50,20,80,15,17,19] 解释:根节点是值为 50 的节点,因为它没有父节点。 结果二叉树如上图所示。
示例 2:
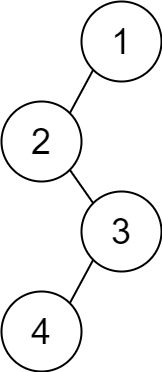
输入:descriptions = [[1,2,1],[2,3,0],[3,4,1]] 输出:[1,2,null,null,3,4] 解释:根节点是值为 1 的节点,因为它没有父节点。 结果二叉树如上图所示。
提示:
1 <= descriptions.length <= 104descriptions[i].length == 31 <= parenti, childi <= 1050 <= isLefti <= 1descriptions所描述的二叉树是一棵有效二叉树