难度: Medium
你总共需要上 numCourses 门课,课程编号依次为 0 到 numCourses-1 。你会得到一个数组 prerequisite ,其中 prerequisites[i] = [ai, bi] 表示如果你想选 bi 课程,你 必须 先选 ai 课程。
- 有的课会有直接的先修课程,比如如果想上课程
1,你必须先上课程0,那么会以[0,1]数对的形式给出先修课程数对。
先决条件也可以是 间接 的。如果课程 a 是课程 b 的先决条件,课程 b 是课程 c 的先决条件,那么课程 a 就是课程 c 的先决条件。
你也得到一个数组 queries ,其中 queries[j] = [uj, vj]。对于第 j 个查询,您应该回答课程 uj 是否是课程 vj 的先决条件。
返回一个布尔数组 answer ,其中 answer[j] 是第 j 个查询的答案。
示例 1:

输入:numCourses = 2, prerequisites = [[1,0]], queries = [[0,1],[1,0]] 输出:[false,true] 解释:课程 0 不是课程 1 的先修课程,但课程 1 是课程 0 的先修课程。
示例 2:
输入:numCourses = 2, prerequisites = [], queries = [[1,0],[0,1]] 输出:[false,false] 解释:没有先修课程对,所以每门课程之间是独立的。
示例 3:
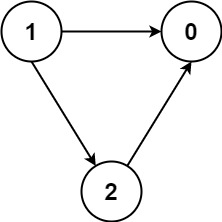
输入:numCourses = 3, prerequisites = [[1,2],[1,0],[2,0]], queries = [[1,0],[1,2]] 输出:[true,true]
提示:
2 <= numCourses <= 1000 <= prerequisites.length <= (numCourses * (numCourses - 1) / 2)prerequisites[i].length == 20 <= ai, bi <= n - 1ai != bi- 每一对
[ai, bi]都 不同 - 先修课程图中没有环。
1 <= queries.length <= 1040 <= ui, vi <= n - 1ui != vi