难度: Medium
给你一个整数 n ,表示一张 无向图 中有 n 个节点,编号为 0 到 n - 1 。同时给你一个二维整数数组 edges ,其中 edges[i] = [ai, bi] 表示节点 ai 和 bi 之间有一条 无向 边。
请你返回 无法互相到达 的不同 点对数目 。
示例 1:
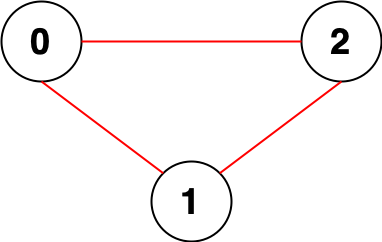
输入:n = 3, edges = [[0,1],[0,2],[1,2]] 输出:0 解释:所有点都能互相到达,意味着没有点对无法互相到达,所以我们返回 0 。
示例 2:
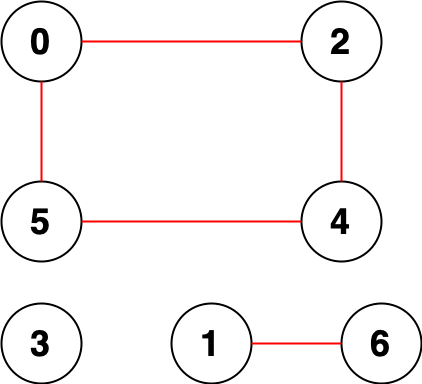
输入:n = 7, edges = [[0,2],[0,5],[2,4],[1,6],[5,4]] 输出:14 解释:总共有 14 个点对互相无法到达: [[0,1],[0,3],[0,6],[1,2],[1,3],[1,4],[1,5],[2,3],[2,6],[3,4],[3,5],[3,6],[4,6],[5,6]] 所以我们返回 14 。
提示:
1 <= n <= 1050 <= edges.length <= 2 * 105edges[i].length == 20 <= ai, bi < nai != bi- 不会有重复边。