难度: Medium
给定一个整数数组,它表示BST(即 二叉搜索树 )的 先序遍历 ,构造树并返回其根。
保证 对于给定的测试用例,总是有可能找到具有给定需求的二叉搜索树。
二叉搜索树 是一棵二叉树,其中每个节点, Node.left 的任何后代的值 严格小于 Node.val , Node.right 的任何后代的值 严格大于 Node.val。
二叉树的 前序遍历 首先显示节点的值,然后遍历Node.left,最后遍历Node.right。
示例 1:
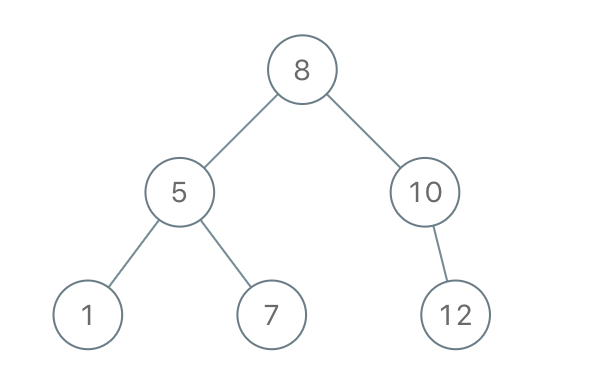
输入:preorder = [8,5,1,7,10,12] 输出:[8,5,10,1,7,null,12]
示例 2:
输入: preorder = [1,3] 输出: [1,null,3]
提示:
1 <= preorder.length <= 1001 <= preorder[i] <= 10^8preorder中的值 互不相同