标签: 字符串
难度: Easy
Excel 表中的一个单元格 (r, c) 会以字符串 "<col><row>" 的形式进行表示,其中:
<col>即单元格的列号c。用英文字母表中的 字母 标识。- 例如,第
1列用'A'表示,第2列用'B'表示,第3列用'C'表示,以此类推。
- 例如,第
<row>即单元格的行号r。第r行就用 整数r标识。
给你一个格式为 "<col1><row1>:<col2><row2>" 的字符串 s ,其中 <col1> 表示 c1 列,<row1> 表示 r1 行,<col2> 表示 c2 列,<row2> 表示 r2 行,并满足 r1 <= r2 且 c1 <= c2 。
找出所有满足 r1 <= x <= r2 且 c1 <= y <= c2 的单元格,并以列表形式返回。单元格应该按前面描述的格式用 字符串 表示,并以 非递减 顺序排列(先按列排,再按行排)。
示例 1:
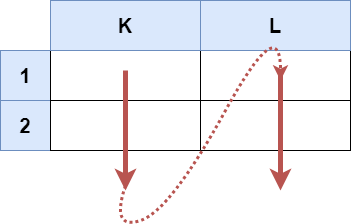
输入:s = "K1:L2" 输出:["K1","K2","L1","L2"] 解释: 上图显示了列表中应该出现的单元格。 红色箭头指示单元格的出现顺序。
示例 2:

输入:s = "A1:F1" 输出:["A1","B1","C1","D1","E1","F1"] 解释: 上图显示了列表中应该出现的单元格。 红色箭头指示单元格的出现顺序。
提示:
s.length == 5'A' <= s[0] <= s[3] <= 'Z''1' <= s[1] <= s[4] <= '9's由大写英文字母、数字、和':'组成