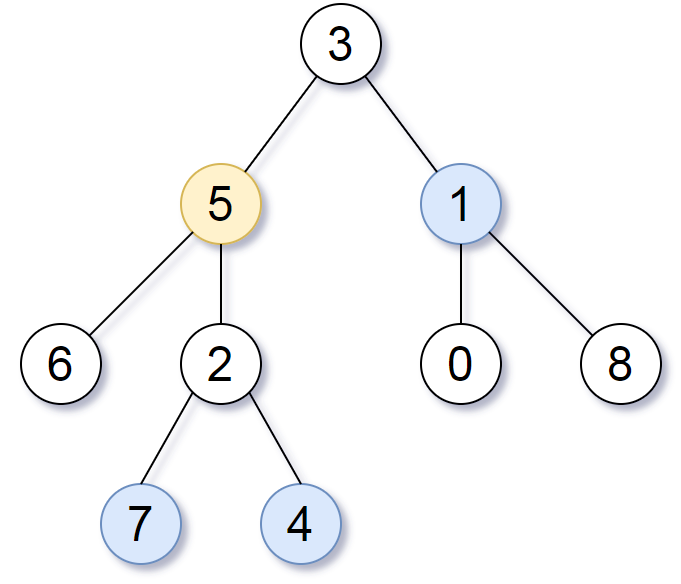
这个题解使用了两个DFS遍历来解决问题。第一个DFS遍历从根节点开始,用于查找目标节点target并记录从根节点到目标节点的路径长度。在找到目标节点时,调用第二个DFS遍历subtree_add,将距离目标节点距离为k的所有节点值加入结果列表。在第一个DFS遍历中,如果当前节点到目标节点的距离为k,则将当前节点值加入结果列表;然后继续递归遍历另一个子树,并将距离加1。最后返回结果列表。
时间复杂度: O(N)
空间复杂度: O(N)
class Solution:
def distanceK(self, root: TreeNode, target: TreeNode, k: int) -> List[int]:
ans = []
# Return distance from node to target if exists, else -1
# Vertex distance: the # of vertices on the path from node to target
def dfs(node):
if not node:
return -1
elif node is target:
subtree_add(node, 0)
return 1
else:
L, R = dfs(node.left), dfs(node.right)
if L != -1:
if L == k: ans.append(node.val)
subtree_add(node.right, L + 1)
return L + 1
elif R != -1:
if R == k: ans.append(node.val)
subtree_add(node.left, R + 1)
return R + 1
else:
return -1
# Add all nodes 'K - dist' from the node to answer.
def subtree_add(node, dist):
if not node:
return
elif dist == k:
ans.append(node.val)
else:
subtree_add(node.left, dist + 1)
subtree_add(node.right, dist + 1)
dfs(root)
return ans