难度: Medium
给你 root1 和 root2 这两棵二叉搜索树。请你返回一个列表,其中包含 两棵树 中的所有整数并按 升序 排序。.
示例 1:
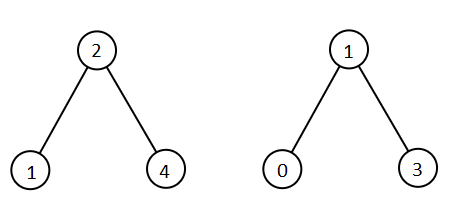
输入:root1 = [2,1,4], root2 = [1,0,3] 输出:[0,1,1,2,3,4]
示例 2:
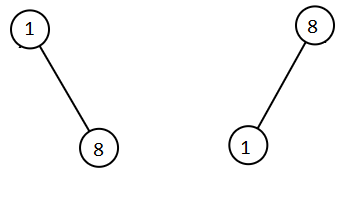
输入:root1 = [1,null,8], root2 = [8,1] 输出:[1,1,8,8]
提示:
- 每棵树的节点数在
[0, 5000]范围内 -105 <= Node.val <= 105
难度: Medium
给你 root1 和 root2 这两棵二叉搜索树。请你返回一个列表,其中包含 两棵树 中的所有整数并按 升序 排序。.
示例 1:
输入:root1 = [2,1,4], root2 = [1,0,3] 输出:[0,1,1,2,3,4]
示例 2:
输入:root1 = [1,null,8], root2 = [8,1] 输出:[1,1,8,8]
提示:
[0, 5000] 范围内-105 <= Node.val <= 105运行时间: 304 ms
内存: 18.7 MB
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class BSTIterator:
def __init__(self, root: Optional[TreeNode]):
self.stack = []
self.dfsLeft(root)
def next(self) -> int:
if len(self.stack) == 0:
return None
root = self.stack.pop()
self.dfsLeft(root.right)
return root.val
def dfsLeft(self, root):
while root is not None:
self.stack.append(root)
root = root.left
class Solution:
def getAllElements(self, root1: TreeNode, root2: TreeNode) -> List[int]:
i1 = BSTIterator(root1)
i2 = BSTIterator(root2)
v1 = i1.next()
v2 = i2.next()
ret = []
while v1 is not None or v2 is not None:
if v1 is not None and (v2 is None or v1 <= v2):
ret.append(v1)
v1 = i1.next()
else:
ret.append(v2)
v2 = i2.next()
return ret
本题解使用了两个 BSTIterator 实例分别对两棵二叉搜索树进行中序遍历,从而得到两个按升序排序的值流。然后,将这两个值流合并成一个有序列表。BSTIterator 类通过迭代的方式实现了中序遍历,它使用一个栈来存储节点,按需进行遍历,从而避免了一次性读取整棵树的开销。在合并过程中,通过比较两个迭代器返回的当前最小值,将较小值添加到结果列表中,并从相应的迭代器获取下一个值,直到两个迭代器都耗尽。
时间复杂度: O(n)
空间复杂度: O(n)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class BSTIterator:
def __init__(self, root: Optional[TreeNode]):
self.stack = []
self.dfsLeft(root) # 初始化时进行一次左侧深度优先搜索
def next(self) -> int:
if len(self.stack) == 0:
return None
root = self.stack.pop() # 弹出栈顶元素,即当前最小元素
self.dfsLeft(root.right) # 探索右子树,寻找下一个最小值
return root.val
def dfsLeft(self, root):
while root is not None:
self.stack.append(root) # 将当前节点压栈
root = root.left # 持续向左走
class Solution:
def getAllElements(self, root1: TreeNode, root2: TreeNode) -> List[int]:
i1 = BSTIterator(root1)
i2 = BSTIterator(root2)
v1 = i1.next() # 从第一棵树获取第一个元素
v2 = i2.next() # 从第二棵树获取第一个元素
ret = []
while v1 is not None or v2 is not None:
if v1 is not None and (v2 is None or v1 <= v2):
ret.append(v1) # 添加较小值到结果列表
v1 = i1.next() # 更新v1为下一个值
else:
ret.append(v2) # 添加较小值到结果列表
v2 = i2.next() # 更新v2为下一个值
return ret
在BSTIterator类的初始化过程中,`dfsLeft`方法被用来执行一次深度优先搜索,专注于树的左侧。这个方法的目的是找到并访问二叉搜索树中的最小元素,这通常是树的最左侧节点。具体实现是通过一个循环,其中将当前节点推入栈中,并将当前节点更新为其左子节点,直到当前节点为`None`。这样做可以确保栈顶始终保存着下一个最小元素。当`next`方法被调用时,栈顶元素(当前最小)被弹出,并对其右子树执行相同的左侧深度优先搜索,以寻找新的最小元素。这种设计允许`BSTIterator`以延迟的方式遍历树,只有在必要时才访问树的部分节点,从而优化性能和内存使用。
在合并两个迭代器生成的值流时,如果一个迭代器已经耗尽(即`next`方法返回`None`),而另一个迭代器仍有元素,题解中的逻辑通过检查每个迭代器返回的值是否为`None`来处理这种情况。如果其中一个值为`None`,则只从另一个仍有元素的迭代器中继续取值。这种方法确保了所有剩余的元素都能被正确地加入到最终的结果列表中,从而完全处理了这种情况。
合并两个有序列表通过比较两个迭代器返回的当前元素,并选择较小者添加到结果列表中,这是高效的因为它保证了每次比较只处理最前面的元素,从而以线性时间复杂度完成合并。这种方法类似于归并排序中的合并过程,是处理两个有序列表合并的标准且高效的策略。虽然这个策略已经很优化,但在特定情况下,如当一个迭代器中的所有元素都比另一个的小,可以通过一些检测来进一步减少比较的次数,直接将剩余元素追加到结果列表中,这可能会带来微小的性能提升。