难度: Medium
给定一个二叉树的根 root 和两个整数 val 和 depth ,在给定的深度 depth 处添加一个值为 val 的节点行。
注意,根节点 root 位于深度 1 。
加法规则如下:
- 给定整数
depth,对于深度为depth - 1的每个非空树节点cur,创建两个值为val的树节点作为cur的左子树根和右子树根。 cur原来的左子树应该是新的左子树根的左子树。cur原来的右子树应该是新的右子树根的右子树。- 如果
depth == 1意味着depth - 1根本没有深度,那么创建一个树节点,值val作为整个原始树的新根,而原始树就是新根的左子树。
示例 1:
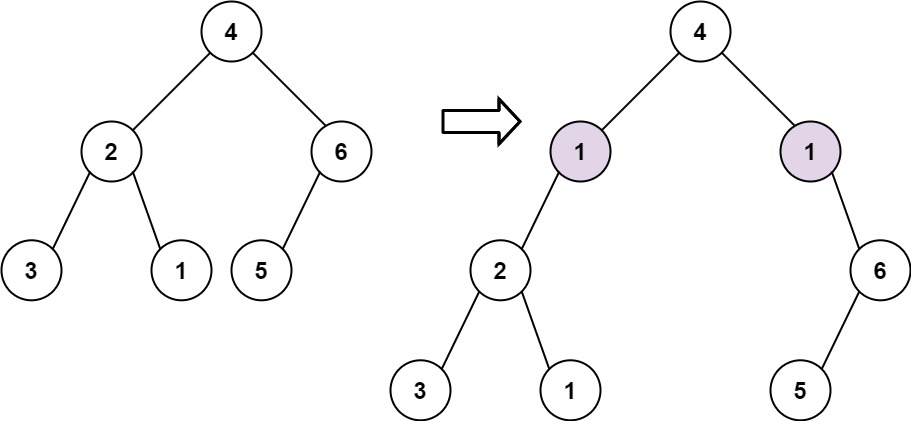
输入: root = [4,2,6,3,1,5], val = 1, depth = 2 输出: [4,1,1,2,null,null,6,3,1,5]
示例 2:
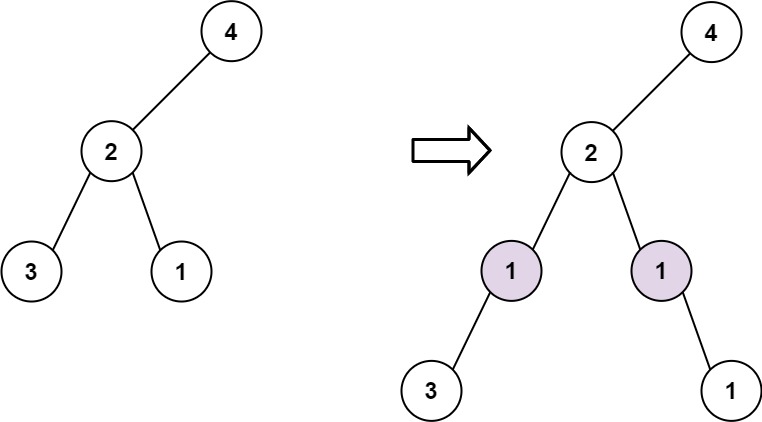
输入: root = [4,2,null,3,1], val = 1, depth = 3 输出: [4,2,null,1,1,3,null,null,1]
提示:
- 节点数在
[1, 104]范围内 - 树的深度在
[1, 104]范围内 -100 <= Node.val <= 100-105 <= val <= 1051 <= depth <= the depth of tree + 1