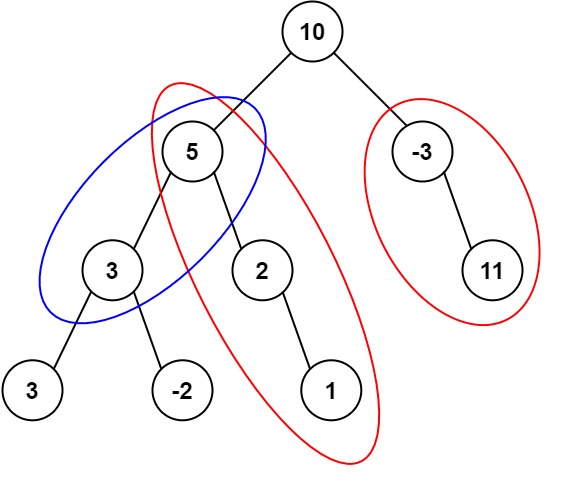
该题解采用了深度优先搜索(DFS)和哈希表来解决问题。首先,我们递归地遍历树的每一个节点,同时维护当前路径的累计和。哈希表`Sumpath`用于存储每个节点到根节点路径上的累计和及其出现的次数。对于每个节点,我们检查`当前累计和 - 目标和`是否已经在哈希表中,如果存在,则说明我们找到了一个有效路径。在递归进入左右子节点之前,更新哈希表以包含当前累计和。在从子节点返回后,为了不影响其他路径,需要将当前累计和的计数减一,以防止它干扰其他路径的计算。这种方法有效地利用了前缀和的概念,即使用累计和减去目标值来快速检查是否存在符合条件的路径。
时间复杂度: O(n)
空间复杂度: O(n)
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def pathSum(self, root: TreeNode, targetSum: int) -> int:
self.ans = 0 # 用于记录路径总数的变量
Sumpath = {0:1} # 哈希表,记录各路径和出现的次数,初始化为0出现一次
def dfs(node, sums):
if not node:
return # 空节点直接返回
sums += node.val # 更新当前路径和
if (sums - targetSum) in Sumpath:
self.ans += Sumpath[sums - targetSum] # 找到有效路径
if sums not in Sumpath:
Sumpath[sums] = 1
else:
Sumpath[sums] += 1
if node.left:
dfs(node.left, sums) # 递归左子树
if node.right:
dfs(node.right, sums) # 递归右子树
Sumpath[sums] -= 1 # 回溯,撤销当前节点对路径和的影响
if not root:
return 0 # 空树直接返回0
dfs(root, 0) # 从根节点开始递归
return self.ans # 返回路径总数